
线性化注意力综述:突破Softmax二次复杂度瓶颈的高效计算方案
大型语言模型在各个领域都展现出了卓越的性能,但其核心组件之一——softmax注意力机制在计算资源消耗方面存在显著局限性。本文将深入探讨如何通过替代方案实现线性时间复杂度,从而突破这一计算瓶颈。
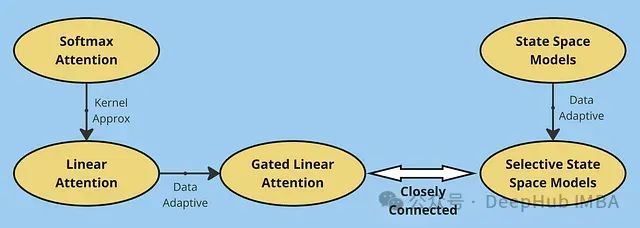
注意力机制基础理论
本文假设读者已经熟悉ChatGPT、Claude等模型及其底层的transformer架构原理。注意力机制是这类模型的核心组件。与传统循环神经网络(RNN)将历史信息压缩存储在固定维度的隐藏状态中不同,注意力机制能够直接访问和选择性利用历史信息。这种机制本质上是在每次预测时,根据当前查询动态检索最相关的历史信息。
transformer架构中的注意力机制通过键(key)、查询(query)和值(value)三个嵌入向量实现信息的动态检索。具体而言transformer的注意力机制通过计算查询向量与所有键向量的相似度,获得注意力权重,再用这些权重对相应的值向量进行加权组合。这一计算过程可以形式化表示为:
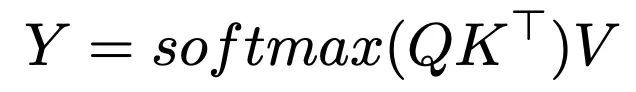
这种机制使模型能够在生成预测时有选择地利用整个上下文中的相关信息。在此过程中使用softmax函数的目的是将原始相似度分数转换为概率分布,这在本质上类似于k近邻机制,即相关性更高的键值对获得更大的权重。
https://avoid.overfit.cn/post/458a98aca6744a55af59ff65db2085e0

 浙公网安备 33010602011771号
浙公网安备 33010602011771号