
SPAR:融合自对弈与树搜索的高性能指令优化框架
大语言模型的指令遵循能力需要模型能够准确识别指令中的细微要求,并在输出中精确体现这些要求。现有方法通常采用偏好学习进行优化,在创建偏好对时直接从模型中采样多个独立响应。但是这种方法可能会引入与指令精确遵循无关的内容变化(例如,同一语义的不同表达方式),这干扰了模型学习识别能够改进指令遵循的关键差异。
针对这一问题,这篇论文提出了SPAR框架,这是一个集成树搜索自我改进的自对弈框架,用于生成有效且具有可比性的偏好对,同时避免干扰因素。通过自对弈机制,大语言模型采用树搜索策略,基于指令对先前的响应进行改进,同时将不必要的变化降至最低。
主要创新点:
- 发现从独立采样响应中获得的偏好对通常包含干扰因素,这些因素阻碍了通过偏好学习提升指令遵循能力
- 提出SPAR,一个创新的自对弈框架,能够在指令遵循任务中实现持续性自我优化
- 构建了包含43K个复杂指令遵循提示的高质量数据集,以及一个能够提升大语言模型指令遵循能力的监督微调数据集
方法论
整体框架
SPAR迭代训练框架如图所示:
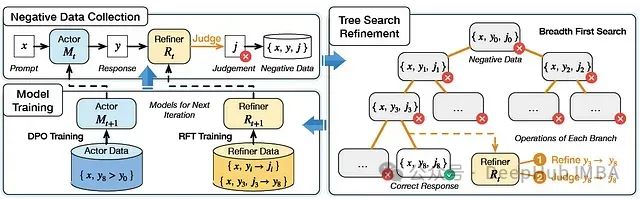
- 在形式化定义中,每次迭代时,给定提示集中的指令x,执行模型生成响应y
- 改进模型负责识别未能准确遵循指令的响应,将其标记为负面响应
- 框架的核心目标是将负面响应优化为符合要求的正确响应
- 收集生成的改进对,通过直接偏好优化(DPO)来优化执行模型
- 同时,应用拒绝采样微调(RFT)提升改进模型性能,为下一轮自我优化做好准备
https://avoid.overfit.cn/post/34fe841bb20f40e898570f8b81cf7ad6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号