
TurboAttention:基于多项式近似和渐进式量化的高效注意力机制优化方案,降低LLM计算成本70%
随着大型语言模型(LLMs)在AI应用领域持续发展,其计算成本也呈现显著上升趋势。数据分析表明,GPT-4的运行成本约为700美元/小时,2023年各企业在LLM推理方面的总支出超过50亿美元。这一挑战的核心在于注意力机制——该机制作为模型处理和关联信息的计算核心,同时也构成了主要的性能瓶颈。
TurboAttention提出了一种全新的LLM信息处理方法。该方法通过一系列优化手段替代了传统的二次复杂度注意力机制,包括稀疏多项式软最大值近似和高效量化技术。初步实现结果显示,该方法可实现70%的计算成本降低,同时保持98%的模型精度。
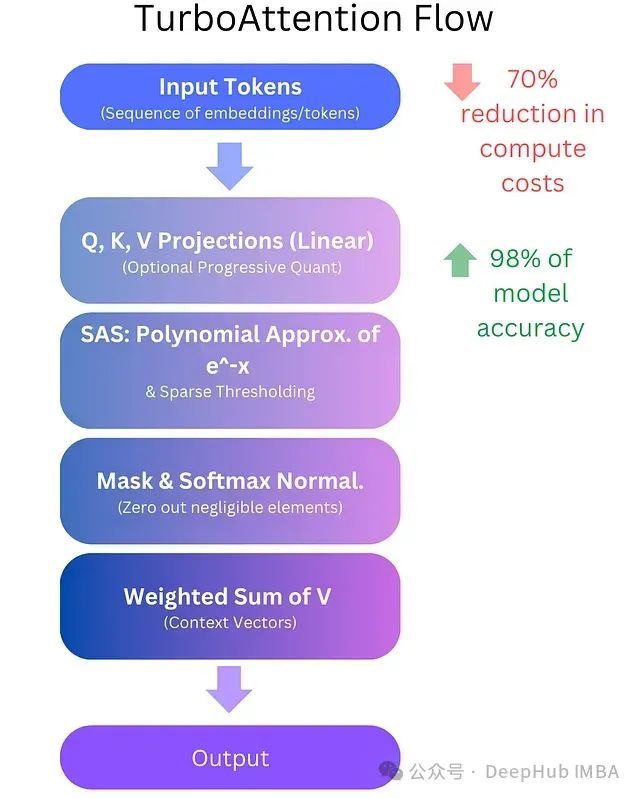
对于规模部署LLM的组织而言,这不仅是性能的提升,更是一项可显著降低运营成本并优化响应时间的技术突破。
本文将从技术层面深入探讨TurboAttention如何实现效率提升,分析其架构创新。
https://avoid.overfit.cn/post/fb11eb14d9044eb7a212179965eb3938

 浙公网安备 33010602011771号
浙公网安备 33010602011771号