Hymba: 结合注意力头和SSM头的创新型语言模型方案
近年来,大语言模型(LLM)在各个领域取得了显著成效。但现有的Transformer架构存在计算复杂度高、内存消耗大等问题。而状态空间模型(SSM)如Mamba虽然具有常数复杂度和优化的硬件性能,但在记忆回溯任务上表现较弱。针对这一问题,NVIDIA提出了Hymba架构,通过在同一层中结合注意力头和SSM头,以实现两种架构优势的互补。
核心创新
Hymba的核心创新主要包括三个方面:
- 并行混合头设计:
- 在同一层内并行集成注意力头和SSM头
- 注意力机制提供高分辨率记忆回溯能力
- SSM提供高效的上下文总结能力
- 这种设计相比Zamba和Jamba等只在不同层使用两种机制的方法更加灵活
- 可学习的元令牌(Meta Tokens):
- 在输入序列前添加可学习的元令牌
- 这些令牌与所有后续令牌交互
- 充当知识的压缩表示
- 提高了回溯和通用任务性能
- KV缓存优化:
- 在层间共享KV缓存
- 大多数层使用滑动窗口注意力机制
- 显著减少了内存和计算成本
架构设计
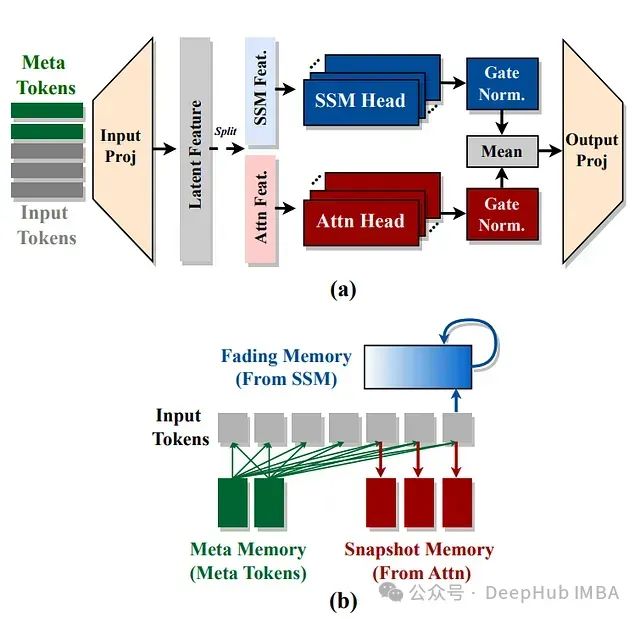
如论文图1所示,Hymba的混合头模块包含:
https://avoid.overfit.cn/post/06def3f77bca4775a8e82a2005b2c19c

 浙公网安备 33010602011771号
浙公网安备 33010602011771号