分布式机器学习系统:设计原理、优化策略与实践经验
人工智能领域正在经历一场深刻的变革。随着深度学习模型的规模呈指数级增长,我们正面临着前所未有的计算挑战。当前最先进的语言模型动辄包含数千亿个参数,这种规模的模型训练已经远远超出了单机系统的处理能力。在这个背景下,分布式机器学习系统已经成为支撑现代人工智能发展的关键基础设施。
分布式机器学习的演进
在深度学习早期,研究人员通常使用单个GPU就能完成模型训练。随着研究的深入,模型架构变得越来越复杂,参数量急剧增长。这种增长首先突破了单GPU的内存限制,迫使研究人员开始探索模型并行等技术。仅仅解决内存问题是不够的。训练时间的持续增长很快成为另一个瓶颈,这促使了数据并行训练方案的发展。
现代深度学习面临的挑战更为严峻。数据规模已经从最初的几个GB扩展到TB甚至PB级别,模型参数量更是达到了数千亿的规模。在这种情况下,即使采用最基础的分布式训练方案也无法满足需求。我们需要一个全方位的分布式训练系统,它不仅要解决计算和存储的问题,还要处理数据管理、通信优化、容错机制等多个层面的挑战。
分布式训练的核心问题
在构建分布式训练系统时,面临着几个根本性的挑战。首先是通信开销问题。在传统的数据并行训练中,每个计算节点都需要频繁地同步模型参数和梯度。随着节点数量的增加,通信开销会迅速成为系统的主要瓶颈。这要求我们必须采用各种优化技术,如梯度压缩、通信计算重叠等,来提高通信效率。
同步策略的选择是另一个关键问题。同步SGD虽然能保证训练的确定性,但可能因为节点间的速度差异导致整体训练速度受限于最慢的节点。而异步SGD虽然能提高系统吞吐量,但可能引入梯度延迟,影响模型收敛。在实际系统中,常常需要在这两种策略间寻找平衡点。
内存管理也同样至关重要。现代深度学习模型的参数量和中间激活值大小已经远超单个设备的内存容量。这要求我们必须精心设计参数分布策略,合理规划计算和存储资源。近年来兴起的ZeRO优化技术就是解决这一问题的典型方案,它通过对优化器状态、梯度和模型参数进行分片,显著降低了每个设备的内存需求。
分布式训练的基本范式
分布式训练最基本的范式是数据并行。这种方式的核心思想是将训练数据分散到多个计算节点,每个节点维护完整的模型副本,通过参数服务器或集合通信来同步梯度信息。数据并行的优势在于实现简单、扩展性好,但它要求每个节点都能存储完整的模型参数。
当模型规模超过单个设备的内存容量时,需要转向模型并行方案。模型并行的核心是将模型参数分布到多个设备上,每个设备只负责部分参数的计算和存储。这种方式虽然能够处理超大规模模型,但实现复杂度较高,且需要精心设计以平衡计算负载和减少设备间通信。
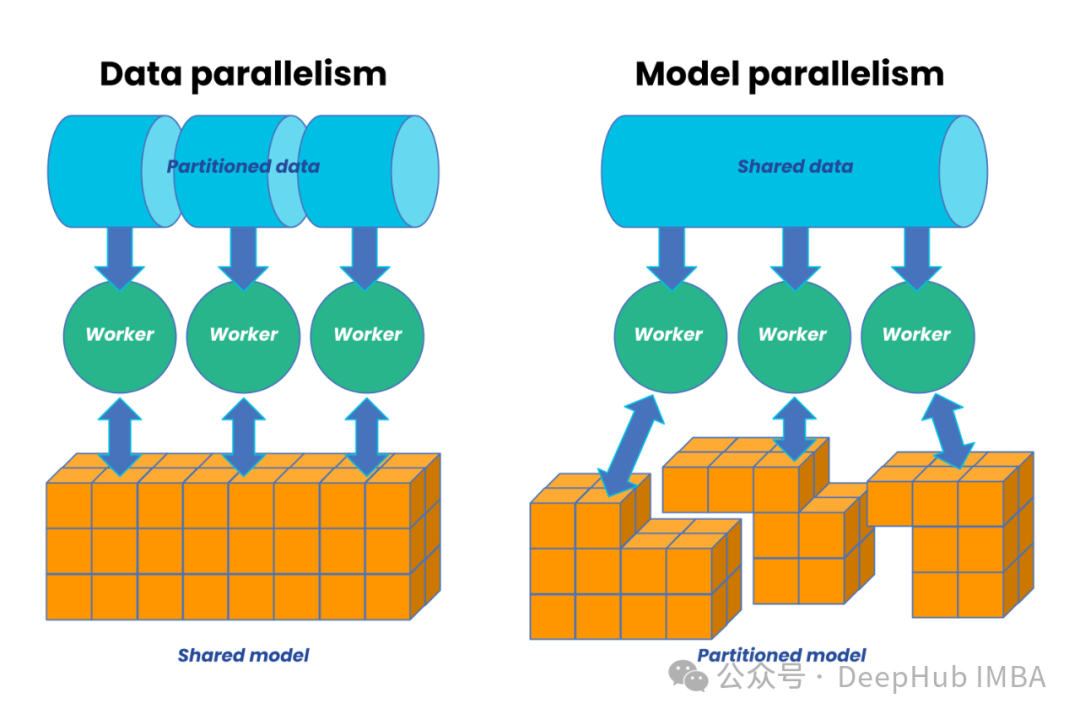
在实际应用中,往往需要将这些基本范式结合起来形成混合并行方案。例如可能在模型架构层面采用流水线并行,在参数层面使用张量并行,同时在外层使用数据并行。这种混合策略能够更好地利用系统资源,但也带来了更高的系统复杂度。
https://avoid.overfit.cn/post/d4e4388735624ec990b5295c77d3b9fa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号