Transformer模型变长序列优化:解析PyTorch上的FlashAttention2与xFormers
随着生成式AI(genAI)模型在应用范围和模型规模方面的持续扩展,其训练和部署所需的计算资源及相关成本也呈现显著增长趋势,模型优化对于提升运行时性能和降低运营成本变得尤为关键。作为现代genAI系统核心组件的Transformer架构及其注意力机制,由于其计算密集型的特性,成为优化的重点对象。
在前面的文章中,我们已经介绍了优化注意力核函数能够显著提升Transformer模型的性能。本文将进一步探讨变长输入序列这一挑战——这是真实世界数据(如文档、代码、时间序列等)的固有特征。
批处理变长输入的技术挑战
在典型的深度学习工作负载中,单个样本在传输至GPU并输入AI模型之前需要进行批处理。批处理不仅能提高计算效率,还能在训练过程中促进模型收敛。通常情况下,批处理操作是通过在新的维度(批次维度)上堆叠所有样本张量来实现的。但是torch.stack操作要求所有张量具有相同的形状,这与变长序列的特性相矛盾。
解决这一挑战的传统方法是将输入序列填充至固定长度后再进行堆叠。这种方法需要在模型中实现适当的掩码机制,以确保输出不受填充元素的影响。在注意力层中,填充掩码用于标识哪些token是填充token,从而在计算注意力时予以忽略(参考PyTorch MultiheadAttention的实现)。这种填充方法会导致GPU资源的显著浪费,增加计算成本并降低开发效率。这一问题在大规模AI模型中表现得尤为突出。
序列连接策略
避免填充的一种替代方案是沿着现有维度连接序列,而非在新维度上堆叠。与torch.stack不同,torch.cat允许处理不同形状的输入张量。连接操作的输出是一个长度等于所有输入序列长度之和的单一序列。为了使这种方案有效,需要为序列配备注意力掩码,确保每个token只关注其原始序列中的其他token,这一过程通常被称为文档掩码。若用N表示所有序列的总长度,采用大O符号表示,则掩码的空间复杂度为*O(N²),注意力层的计算复杂度也为O(N²)*(因为它需要在计算注意力分数后才应用掩码),这使得该方案的效率极低。
注意力层优化技术
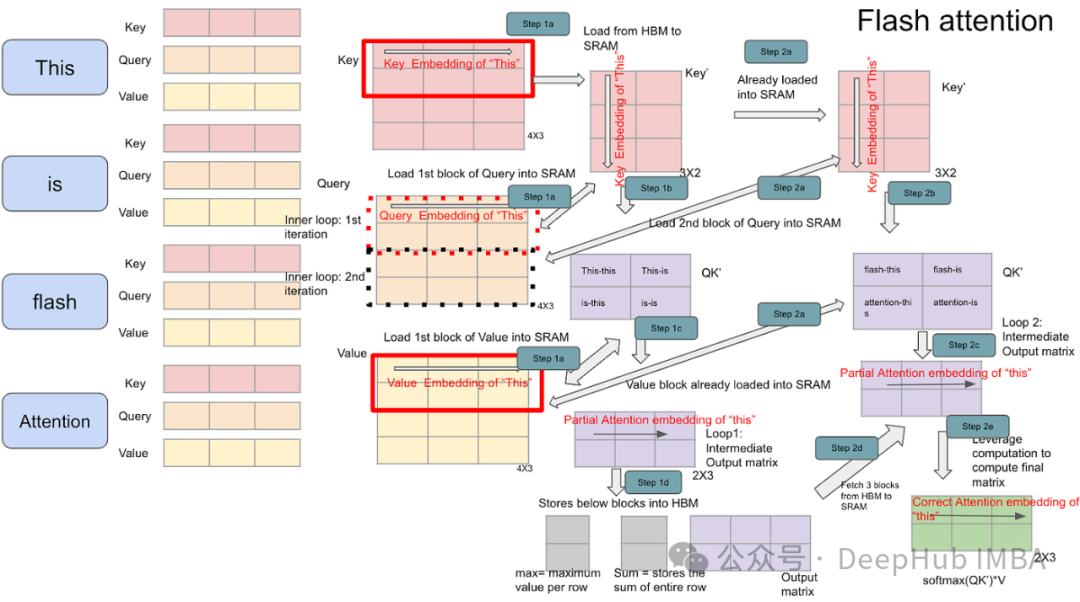
针对上述问题,专门设计的注意力层提供了解决方案。与标准注意力层不同,这类优化的注意力核函数采用了更高效的计算策略。标准注意力层会计算完整的O(N²)注意力分数集合后再应用掩码,而优化后的核函数从设计之初就只计算实际需要的分数。本文将介绍几种具有不同特点的解决方案。
与HuggingFace模型的集成方案
对于使用预训练模型的开发团队来说,迁移至这些优化方案可能存在一定难度。本文将演示如何通过HuggingFace的API简化这一过程,使开发人员能够以最小的代码改动实现这些优化技术的集成。
- 本文中涉及的平台、库或优化技术的使用并不构成对其的推荐。最适合的技术选择将取决于具体应用场景的要求。
- 部分讨论的API仍处于原型或测试阶段,其接口可能在未来发生变化。
- 文中提供的代码示例仅供参考,不保证其在生产环境中的适用性、最优性或稳定性。
https://avoid.overfit.cn/post/ded3ece991804f8992089ff23e82b7e9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号