
解读双编码器和交叉编码器:信息检索中的向量表示与语义匹配
在信息检索领域(即从海量数据中查找相关信息),双编码器和交叉编码器是两种至关重要的工具。它们各自拥有独特的工作机制、优势和局限性。本文将深入探讨这两种核心技术。
双编码器:高效的大规模检索
双编码器分别处理文档和搜索查询。可以将其类比为两个人独立工作:一人负责概括文档,另一人则专注于搜索查询,两者之间互不交流。“双”字体现了查询和文档的独立编码过程。
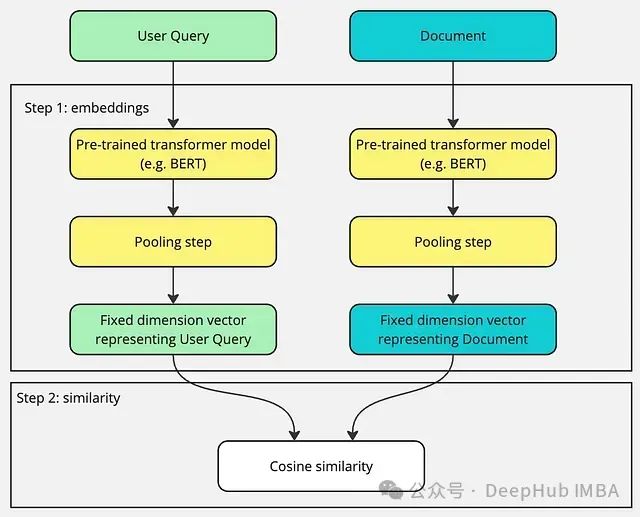
用户查询和文档向量嵌入使用相同的嵌入模型计算,但两者完全隔离。
https://avoid.overfit.cn/post/d9d5114419294e2aa30f3643be4a4a2e

 浙公网安备 33010602011771号
浙公网安备 33010602011771号