
通过pin_memory 优化 PyTorch 数据加载和传输:工作原理、使用场景与性能分析
在 PyTorch 框架中,有一个看似简单的设置可以对模型性能产生重大影响:
pin_memory
。这个设置具体起到了什么作用,为什么需要关注它呢?如果你正在处理大规模数据集、实时推理或复杂的多 GPU 训练任务,将
pin_memory
设为
True
可以提高 CPU 与 GPU 之间的数据传输速度,有可能节省关键的毫秒甚至秒级时间,而这些时间在数据密集型工作流中会不断累积。
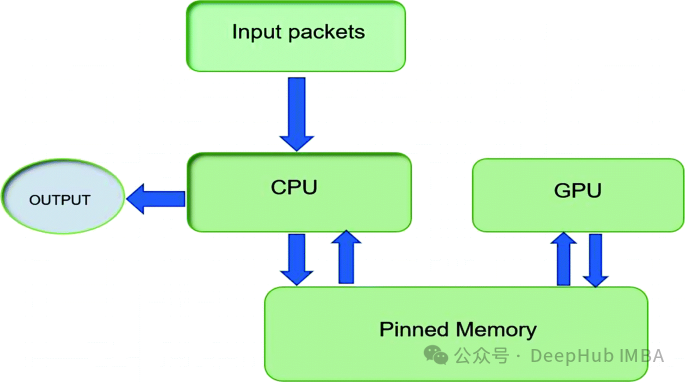
你可能会产生疑问:为什么
pin_memory
*如此重要?*其本质在于:
pin_memory
设为
True
时会在 CPU 上分配页面锁定(或称为"固定")的内存,加快了数据向 GPU 的传输速度。本文将深入探讨何时以及为何启用这一设置,帮助你优化 PyTorch 中的内存管理和数据吞吐量。
https://avoid.overfit.cn/post/cfbf700dc65741009372cf73ad53af36

 浙公网安备 33010602011771号
浙公网安备 33010602011771号