LLM-Mixer: 融合多尺度时间序列分解与预训练模型,可以精准捕捉短期波动与长期趋势
近年来,大型语言模型(Large Language Models,LLMs)在自然语言处理领域取得了显著进展。受此启发,研究人员开始探索将LLMs应用于时间序列预测任务的可能性。由于时间序列数据与文本数据在特征上存在显著差异,直接将LLMs应用于时间序列预测仍面临诸多挑战。
为了解决这一问题,Jin等人提出了一种名为LLM-Mixer的创新框架,旨在通过引入多尺度时间序列分解,使LLMs更好地适应时间序列预测任务。该研究的主要目的是提高预测精度,捕捉时间序列数据中的短期波动和长期趋势。
研究动机与挑战
时间序列预测在金融、能源管理、医疗保健等诸多领域具有重要应用价值。传统的预测模型,如ARIMA和指数平滑法,在处理复杂的非线性、非平稳的真实世界时间序列数据时,往往面临局限性。近年来,深度学习模型,如CNN和RNN,在时间序列预测任务中展现出优异表现,但它们在捕捉长期依赖关系方面仍存在不足。
与此同时,预训练的LLMs凭借其在少样本/零样本学习、多模态知识整合和复杂推理等方面的出色能力,正被广泛应用于各个领域。然而,将LLMs直接用于时间序列预测仍面临以下挑战:
- 时间序列数据通常呈现连续且不规则的模式,与LLMs所处理的离散文本数据存在显著差异;
- 时间序列数据通常具有多个时间尺度,包括短期波动和长期趋势,单一尺度的建模难以兼顾这些复杂模式;
- LLMs通常处理固定长度的序列,这意味着模型可能只捕捉到短期依赖关系,而忽略了长期趋势。
LLM-Mixer的创新之处
针对上述挑战,Jin等人提出的LLM-Mixer框架主要有以下创新点:
- 引入多尺度时间序列分解,将原始时间序列数据分解为多个时间分辨率,以更好地捕捉短期波动和长期趋势;
- 使用三种类型的嵌入:令牌嵌入、时间嵌入和位置嵌入,丰富多尺度时间序列的特征表示;
- 采用可分解历史混合(Past-Decomposable-Mixing,PDM)模块,混合不同尺度的历史信息,并将复杂的时间序列分解为独立的季节性和趋势组件;
- 利用预训练的LLMs处理多尺度数据和文本提示,充分利用LLMs的语义知识和多尺度信息生成预测。
图1展示了LLM-Mixer的总体框架:
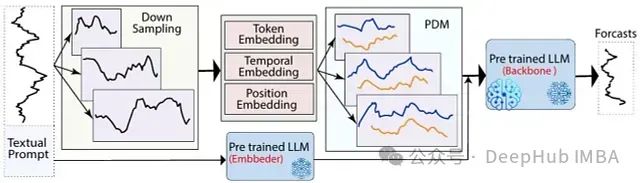
图1:用于时间序列预测的LLM-Mixer框架。时间序列数据被下采样到多个尺度并用嵌入进行丰富。这些多尺度表示由可分解历史混合(Past-Decomposable-Mixing, PDM)模块处理,然后输入到预训练的LLM中,在文本描述的指引下生成预测。
https://avoid.overfit.cn/post/969183c739824f6c91786dfb8e0893e3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号