
MoH:融合混合专家机制的高效多头注意力模型及其在视觉语言任务中的应用
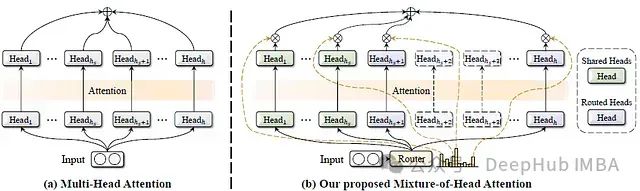
在深度学习领域,多头注意力机制一直是Transformer模型的核心组成部分,在自然语言处理和计算机视觉任务中取得了巨大成功。然而,研究表明并非所有的注意力头都具有同等重要性,许多注意力头可以在不影响模型精度的情况下被剪枝。基于这一洞察,这篇论文提出了一种名为混合头注意力(Mixture-of-Head attention, MoH)的新架构,旨在提高注意力机制的效率,同时保持或超越先前的准确性水平。
研究的主要目的包括:
1、提出一种动态注意力头路由机制,使每个token能够自适应地选择适当的注意力头。
2、在不增加参数数量的情况下,提高模型性能和推理效率。
3、验证MoH在各种流行的模型框架中的有效性,包括Vision Transformers (ViT)、Diffusion models with Transformers (DiT)和Large Language Models (LLMs)。
4、探索将预训练的多头注意力模型(如LLaMA3-8B)继续调优为MoH模型的可能性。
https://avoid.overfit.cn/post/41a8250d1e4c420cafb23ecfb07b073d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号