
利用未标记数据的半监督学习在模型训练中的效果评估
数据科学家在实践中经常面临的一个关键挑战是缺乏足够的标记数据来训练可靠且准确的模型。标记数据对于监督学习任务(如分类或回归)至关重要。但是在许多领域,获取标记数据往往成本高昂、耗时或不切实际。相比之下,未标记数据通常较易获取,但无法直接用于模型训练。
如何利用未标记数据来改进监督学习模型?这正是半监督学习的应用场景。半监督学习是机器学习的一个分支,它结合标记和未标记数据来训练模型,旨在获得比仅使用标记数据更优的性能。半监督学习的基本原理是,未标记数据可以提供关于数据底层结构、分布和多样性的有用信息,从而帮助模型更好地泛化到新的和未见过的样本。
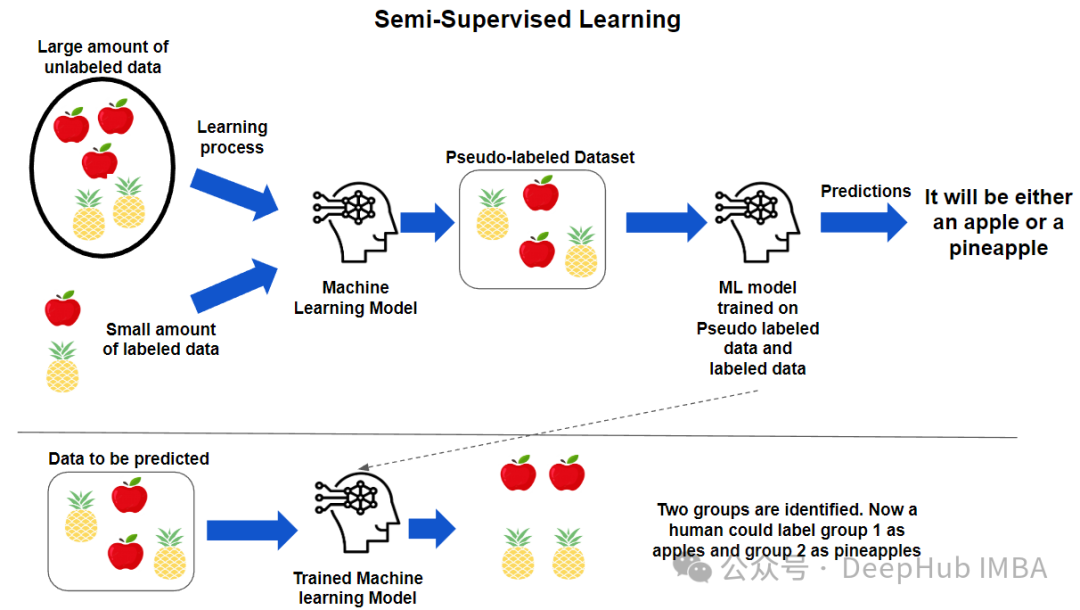
本文将介绍三种适用于不同类型数据和任务的半监督学习方法。我们还将在一个实际数据集上评估这些方法的性能,并与仅使用标记数据的基准进行比较。
https://avoid.overfit.cn/post/9db781a0b2e941fca451fed2be16b09a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号