MemLong: 基于记忆增强检索的长文本LLM生成方法
本文将介绍MemLong,这是一种创新的长文本语言模型生成方法。MemLong通过整合外部检索器来增强模型处理长上下文的能力,从而显著提升了大型语言模型(LLM)在长文本处理任务中的表现。
核心概念
MemLong的设计理念主要包括以下几点:
- 高效扩展LLM上下文窗口的轻量级方法。
- 利用不可训练的外部记忆库存储历史上下文和知识。
- 通过检索相关的块级键值(K-V)对来增强模型输入。
- 适用于各种仅解码器的预训练语言模型。
- 引入额外的记忆检索(ret-mem)组件和检索因果注意力模块。
MemLong的工作流程如图1所示:
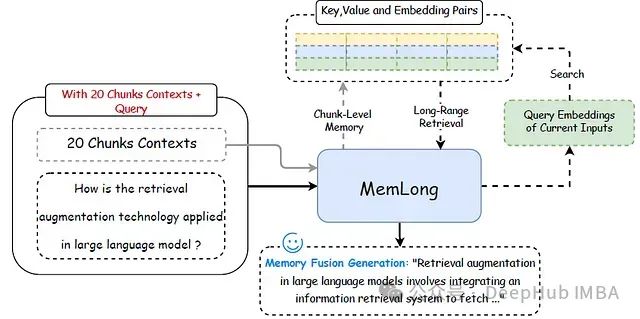
图1:MemLong的记忆和检索过程示意图
https://avoid.overfit.cn/post/886d820cba6240bfb005e4c2378fe2e8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号