优化采样参数提升大语言模型响应质量:深入分析温度、top_p、top_k和min_p的随机解码策略
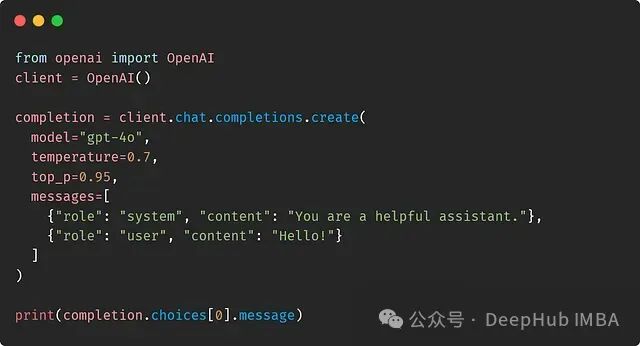
当向大语言模型(LLM)提出查询时,模型会为其词汇表中的每个可能标记输出概率值。从这个概率分布中采样一个标记后,我们可以将该标记附加到输入提示中,使LLM能够继续输出下一个标记的概率。这个采样过程可以通过诸如
temperature
和
top_p
等参数进行精确控制。但是你是否曾深入思考过temperature和top_p参数的具体作用?
本文将详细解析并可视化定义LLM输出行为的采样策略。通过深入理解这些参数的作用机制并根据具体应用场景进行调优,可以显著提升LLM生成输出的质量。
本文的介绍可以采用VLLM作为推理引擎,并使用微软最新发布的Phi-3.5-mini-instruct模型,结合AWQ量化技术,可以在配备NVIDIA GeForce RTX 2060 GPU的笔记本电脑中运行。
https://avoid.overfit.cn/post/6a30e6cfd2ac4f0d89edb4235e30c876

 浙公网安备 33010602011771号
浙公网安备 33010602011771号