
基于重要性加权的LLM自我改进:考虑分布偏移的新框架
LLM自我改进的典型范式是在自生成数据上训练LLM,但是其中的部分数据可能有害,所以应该被过滤掉。但是目前的工作主要采用基于答案正确性的过滤策略,在这篇论文中,证明过滤掉正确但具有高分布偏移程度(DSE)的样本也可以有利于自我改进的结果。
论文的主要贡献如下:
- 提出了一个称为DS权重的指标,借助一个微小的有效集来近似LLM自生成数据的DSE
- 利用DS权重,构建了一个新颖的自我改进框架,称为基于重要性加权的自我改进(IWSI),其中过滤策略同时考虑了答案正确性和DSE
- 实证检验了论文提出方法的有效性,分析了高DSE样本对LLM自我改进的影响,并探讨了DS权重如何与其他过滤标准相互作用
方法论
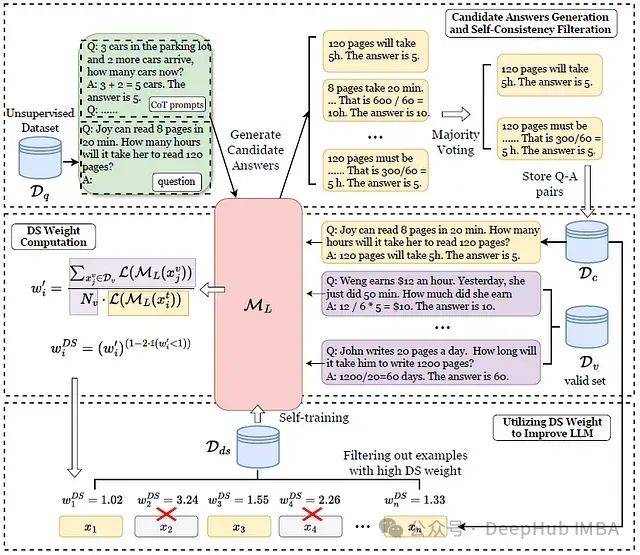
给定一个无监督(仅问题)数据集D𝑞,首先使用预训练的LLM M𝐿使用CoT提示每个问题生成多个候选答案以及推理思路,然后IWSI使用多数投票选择最一致的答案和相应的思路,存储在过滤后的数据集D𝑐中在微小有效集D𝑣的帮助下,IWSI计算D𝑐中每个数据点的DS权重。IWSI通过保留DS权重最低的𝑘%样本将D𝑐过滤成D𝑑𝑠,最后对M𝐿进行自我训练
https://avoid.overfit.cn/post/f89e3b7f26f04cee892c3700a28618fa

 浙公网安备 33010602011771号
浙公网安备 33010602011771号