基于距离度量学习的异常检测:一种通过相关距离度量的异常检测方法
异常通常被定义为数据集中与大多数其他项目非常不同的项目。或者说任何与所有其他记录(或几乎所有其他记录)显著不同的记录,并且与其他记录的差异程度超出正常范围,都可以合理地被认为是异常。
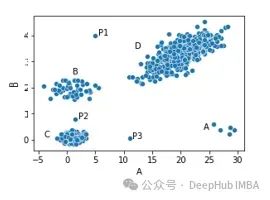
例如上图显示的数据集中,我们有四个簇(A、B、C和D)和三个位于这些簇之外的点:P1、P2和P3可能被视为异常,因为它们每个都远离所有其他点 - 也就是说,它们与大多数其他点有显著差异。
同样,簇A只有五个点。虽然这些点彼此相当接近,但它们远离所有其他点,所以也可能被认为是异常。内点(较大簇内的点)都非常接近大量其他点。例如,簇C中间的任何点都非常接近许多其他点(即与许多其他点非常相似),所以不会被视为异常。
我们可以用许多其他方式来看待异常,实际上许多其他方法也用于异常检测 - 例如基于频繁项集、关联规则、压缩、马尔可夫模型等的异常检测方法。但是事实上,最常见的异常检测算法背后的基本思想,包括kNN、LOF(局部异常因子)、Radius等众多算法,都是使用数据见距离来进行计算的。
这就引出了一个问题:如何量化一条记录与其他记录的差异程度。在异常检测中最常见的一些包括欧几里得距离、曼哈顿距离和Gower距离,以及许多类似的度量。
但在本文中,将一种非常通用且可能未被充分使用的方法,用于计算表格数据中两条记录之间的差异,这对异常检测非常有用,称为距离度量学习 - 以及一种专门应用于异常检测的方法。
https://avoid.overfit.cn/post/81746cc2ef314702a838c2aaa9d57b6b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号