
使用BatchNorm替代LayerNorm可以减少Vision Transformer训练时间和推理时间
以Vision Transformer (ViT)的发现为先导的基于transformer的架构在计算机视觉领域引发了一场革命。对于广泛的应用,ViT及其各种变体已经有效地挑战了卷积神经网络(CNN)作为最先进架构的地位。尽管取得了一些成功,但是ViT需要更长的训练时间,并且对于小型到中型输入数据大小,推理速度较慢。因此研究更快训练和推理Vision Transformer就变成了一个重要的方向。
在以前我们都是知道,Batch Normalization(以下简称BN)的方法最早由Ioffe&Szegedy在2015年提出,主要用于解决在深度学习中产生的ICS(Internal Covariate Shift)的问题。若模型输入层数据分布发生变化,则模型在这波变化数据上的表现将有所波动,输入层分布的变化称为Covariate Shift,解决它的办法就是常说的Domain Adaptation
而在transformer上使用Layer Normalization(以下简称LN)的方法,用于解决BN无法很好地处理文本数据长度不一的问题,但是对于VIT来说,图像的块数是固定的,并且长度也是固定的,那么能不能用BN来替代LN呢?
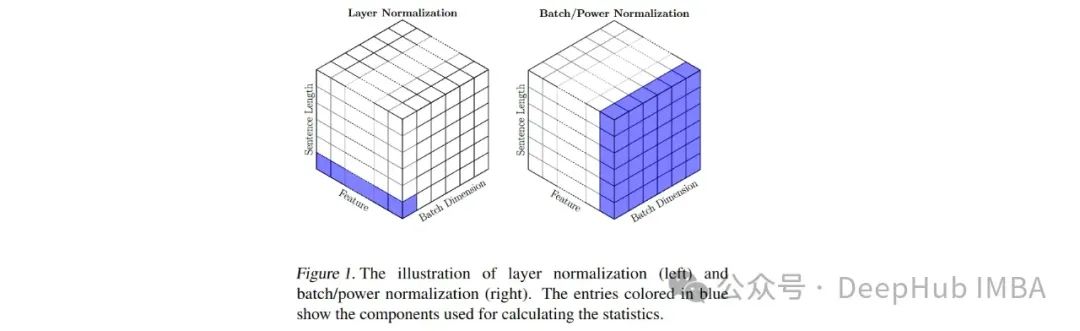
本文我们将详细探讨ViT的一种修改,这将涉及用批量归一化(BatchNorm)替换层归一化(LayerNorm) - transformer的默认归一化技术。ViT有一个仅编码器的架构,transformer编码器由两个不同的模块组成 - 多头自注意力(MHSA)和前馈网络(FFN)。所以我门将讨论这种模型的两个版本。第一个模型将涉及仅在前馈网络中实现BatchNorm层 - 这将被称为ViTBNFFN( 前馈网络中带有BatchNorm的Vision Transformer**)** 。第二个模型将涉及在Vision Transformer的所有地方用BatchNorm替换LayerNorm - 我将这个模型称为ViTBN( 带有BatchNorm的Vision Transformer**)**。因此,模型ViTBNFFN将同时涉及LayerNorm(在MHSA中)和BatchNorm(在FFN中),而ViTBN将仅涉及BatchNorm。
https://avoid.overfit.cn/post/94913313e55b4f3db99d7b07aec57e11

 浙公网安备 33010602011771号
浙公网安备 33010602011771号