
大语言模型的Scaling Law:如何随着模型大小、训练数据和计算资源的增加而扩展
人工智能的世界正在经历一场革命,大型语言模型正处于这场革命的前沿,它们似乎每天都在变得更加强大。从BERT到GPT-3再到PaLM,这些AI巨头正在推动自然语言处理可能性的边界。但你有没有想过是什么推动了它们能力的飞速提升?
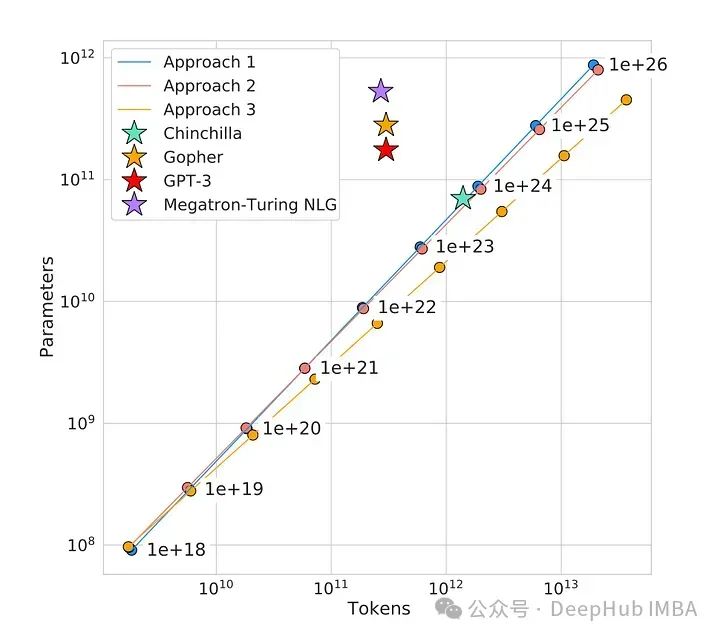
在这篇文章中,我们将介绍使这些模型运作的秘密武器——一个由三个关键部分组成的法则:模型大小、训练数据和计算能力。通过理解这些因素如何相互作用和规模化,我们将获得关于人工智能语言模型过去、现在和未来的宝贵见解。
https://avoid.overfit.cn/post/9867397a40334064b0bbd470e588c4c2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号