用PyTorch从零开始编写DeepSeek-V2
DeepSeek-V2是一个强大的开源混合专家(MoE)语言模型,通过创新的Transformer架构实现了经济高效的训练和推理。该模型总共拥有2360亿参数,其中每个令牌激活21亿参数,支持最大128K令牌的上下文长度。
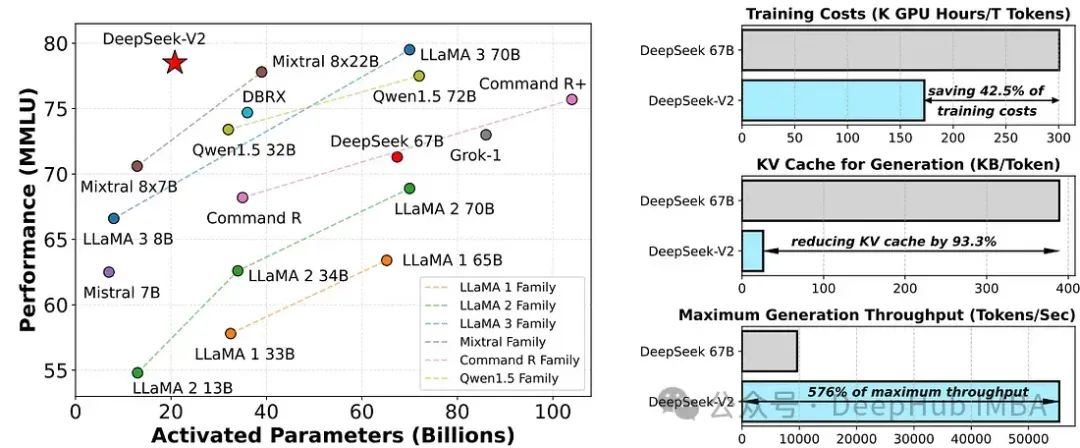
在开源模型中,DeepSeek-V2实现了顶级性能,成为最强大的开源MoE语言模型。在MMLU(多模态机器学习)上,DeepSeek-V2以较少的激活参数实现了顶尖的性能。与DeepSeek 67B相比,DeepSeek-V2显著提升了性能,降低了42.5%的训练成本,减少了93.3%的KV缓存,并将最大生成吞吐量提高了5.76倍。
我们这里主要实现DeepSeek的主要改进:多头隐性注意力、细粒度专家分割和共享的专家隔离
https://avoid.overfit.cn/post/317a967c8dac42ee98f96d8390851476

 浙公网安备 33010602011771号
浙公网安备 33010602011771号