LLM代理应用实战:构建Plotly数据可视化代理
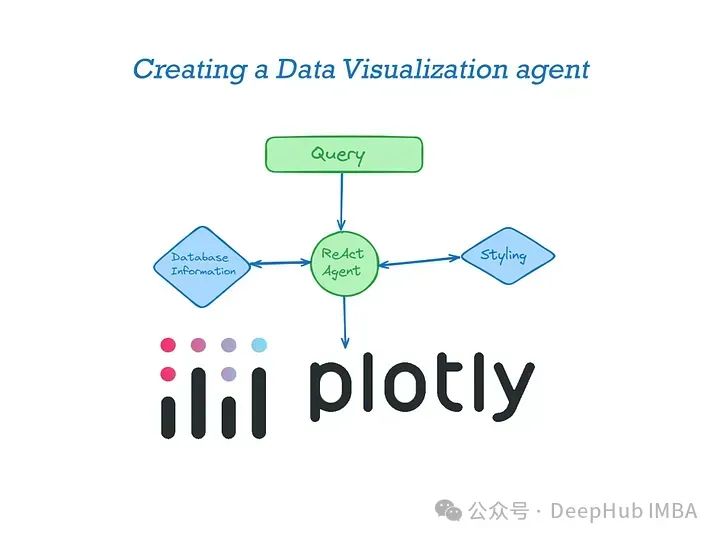
如果你尝试过像ChatGPT这样的LLM,就会知道它们几乎可以为任何语言或包生成代码。但是仅仅依靠LLM是有局限的。对于数据可视化的问题我们需要提供一下的内容
描述数据:模型本身并不知道数据集的细节,比如列名和行细节。手动提供这些信息可能很麻烦,特别是当数据集变得更大时。如果没有这个上下文,LLM可能会产生幻觉或虚构列名,从而导致数据可视化中的错误。
样式和偏好:数据可视化是一种艺术形式,每个人都有独特的审美偏好,这些偏好因图表类型和信息而异。不断地为每个可视化提供不同的风格和偏好是很麻烦的。而配备了风格信息的代理可以简化这一过程,确保一致和个性化的视觉输出。
如果每次于LLM进行交互都附带这些内容会导致请求过于复杂,不利于用户的输入,所以这次我们构建一个数据可视化的代理,通过代理我们只需提供很少的信息就能够让LLM生成我们定制化的图表。
https://avoid.overfit.cn/post/b7250a6a029d46adb2c5948eb71b5d28

 浙公网安备 33010602011771号
浙公网安备 33010602011771号