
2024年6月后2周重要的大语言模型论文总结:LLM进展、微调、推理和对齐
本文总结了2024年6月后两周发表的一些最重要的大语言模型论文。这些论文涵盖了塑造下一代语言模型的各种主题,从模型优化和缩放到推理、基准测试和增强性能。
LLM进展与基准
1、 BigCodeBench: Benchmarking Code Generation with Diverse Function Calls and Complex Instructions
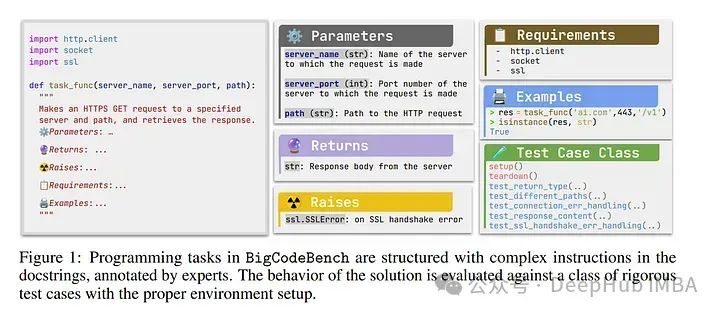
自动化软件工程近期受益于大型语言模型(LLMs)在编程领域的进展。尽管现有基准测试表明LLMs能够执行各种软件工程任务,但它们的评估主要限于短小且自成一体的算法任务。
解决具有挑战性和实用性的编程任务,需要利用各种函数调用作为工具,如数据分析和网页开发。使用多个工具解决任务需要通过准确理解复杂指令来进行组合推理。
满足这两种特性对LLMs来说是一个巨大的挑战。为了评估LLMs在解决具有挑战性和实用性的编程任务方面的表现,论文引入了一个基准测试Bench,挑战LLMs从139个库和7个领域调用多个函数作为工具,用于1,140个细粒度的编程任务。
为了严格评估LLMs,每个编程任务包含5.6个测试用例,平均分支覆盖率为99%。提出了一个以自然语言为导向的Bench变体,Benchi,它自动将原始文档字符串转换为仅包含关键信息的简短指令。
我们对60个LLMs的广泛评估显示,LLMs尚未能够按照复杂指令精确使用函数调用,得分最高为60%,远低于人类的97%表现。这些结果强调了该领域需要进一步发展的必要性。
https://avoid.overfit.cn/post/42caafd81dfb40f387c59747c6a96417

 浙公网安备 33010602011771号
浙公网安备 33010602011771号