DeepMind的新论文,长上下文的大语言模型能否取代RAG或者SQL这样的传统技术呢?
长上下文大型语言模型(LCLLMs)确实引起了一些关注。这类模型可能使某些任务的解决更加高效。例如理论上可以用来对整本书进行总结。有人认为,LCLLMs不需要像RAG这样的外部工具,这有助于优化并避免级联错误。但是也有许多人对此持怀疑态度,并且后来的研究表明,这些模型并没有真正利用长上下文。还有人声称,LCLLMs会产生幻觉错误,而其他研究则表明,较小的模型也能高效解决这些任务。
关于长上下文大型语言模型是否真正利用其巨大的上下文窗口,以及它们是否真的更优越,这些问题仍然没有定论,因为目前还没有能够测试这些模型的基准数据集。
但是要充分发挥LCLLMs的潜力,需要对真正的长上下文任务进行严格评估,这些任务在现实世界应用中很有用。现有的基准测试在这方面表现不佳,它们依赖于像“大海捞针”这样的合成任务或固定长度的数据集,这些数据集无法跟上“长上下文”的不断发展的定义。
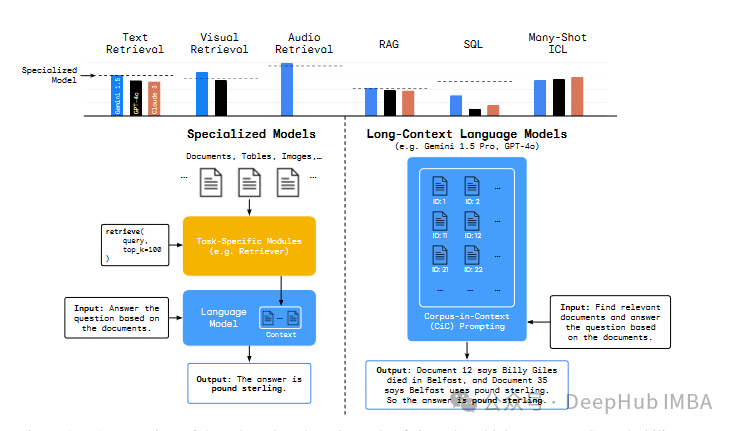
所以DeepMind最近构建了一个名为Long-Context Frontiers(LOFT)新基准数据集,试图解决这一不足。这个新数据集包括六个任务,涵盖了35个数据集,这些数据集跨越文本、视觉和音频模态。
https://avoid.overfit.cn/post/8e48436858674be0a0b9306afecb13bc

 浙公网安备 33010602011771号
浙公网安备 33010602011771号