2024年6月上半月30篇大语言模型的论文推荐
大语言模型(LLMs)在近年来取得了快速发展。本文总结了2024年6月上半月发布的一些最重要的LLM论文,可以让你及时了解最新进展。
LLM进展与基准测试
1、WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild
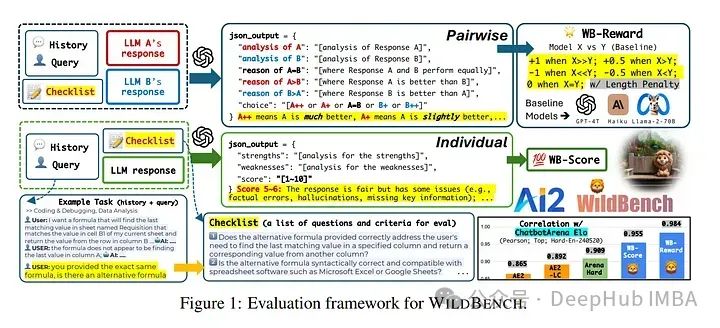
WildBench是一个自动评估框架,使用具有挑战性的、现实世界中的用户查询来基准测试大语言模型(LLMs)。WildBench包含1,024个任务和精心挑选超过一百万个人机对话日志。
为了使用WildBench进行自动评估,论文开发了两个指标,WB-Reward和WB-Score,这些指标可以使用高级LLMs如GPT-4-turbo计算。
https://avoid.overfit.cn/post/ee1689e382f54777b72dbb4a4610a64a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号