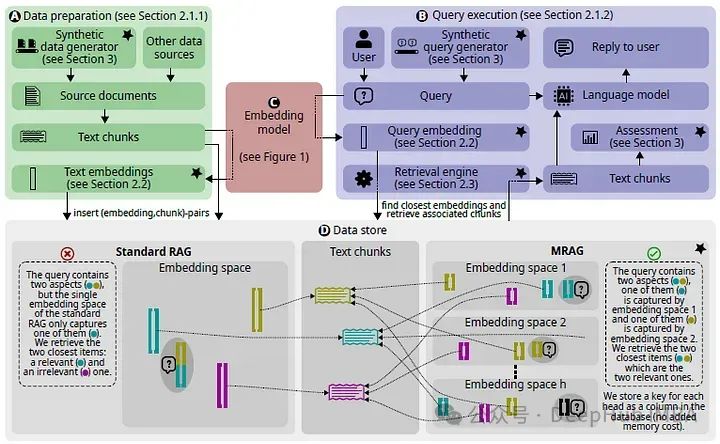
Multi-Head RAG:多头注意力的激活层作为嵌入进行文档检索
现有的RAG解决方案可能因为最相关的文档的嵌入可能在嵌入空间中相距很远,这样会导致检索过程变得复杂并且无效。为了解决这个问题,论文引入了多头RAG (MRAG),这是一种利用Transformer的多头注意层的激活而不是解码器层作为获取多方面文档的新方案。
MRAG
不是利用最后一个前馈解码器层为最后一个令牌生成的单个激活向量,而是利用最后一个注意力层为最后一个令牌生成的H个单独的激活向量,然后通过矩阵Wo(结合所有注意头结果的线性层)对其进行处理。
可以公式化为一组嵌入S = {ek∀k},其中ek = headk(xn),它是输入的最后一个标记xn上的所有注意力头的输出的集合
由于多个头的处理不会改变输出向量的大小,因此具有与标准RAG相同的嵌入空间,这种使用解码器块的多头注意力部分的激活作为嵌入有助于捕获数据的潜在多面性,并且不增加空间需求
MRAG处理流程
https://avoid.overfit.cn/post/aa09461b01a04958a8783872587166eb

 浙公网安备 33010602011771号
浙公网安备 33010602011771号