
Block Transformer:通过全局到局部的语言建模加速LLM推理
在基于transformer的自回归语言模型(LMs)中,生成令牌的成本很高,这是因为自注意力机制需要关注所有之前的令牌,通常通过在自回归解码过程中缓存所有令牌的键值(KV)状态来解决这个问题。但是,加载所有先前令牌的KV状态以计算自注意力分数则占据了LMs的推理的大部分成本。
在这篇论文中,作者提出了Block Transformer架构,该架构通过在较低层次之间的粗糙块(每个块代表多个令牌)的自注意力来模拟全局依赖性,并在较高层次的每个局部块内解码细粒度的令牌,如下图所示。
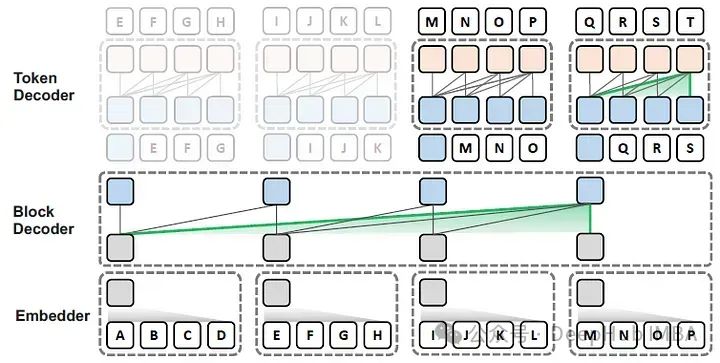
论文的主要贡献包括:
- 发现了在自回归变换器中,全局和局部建模在推理时的核心作用和好处,特别是局部模块的重要性。
- 利用这些见解可以优化架构中的推理吞吐量,与普通transformers相比,显著提高了性能与吞吐量
https://avoid.overfit.cn/post/6867c4c1e9f24d3fb5fef2cd2ecfd989

 浙公网安备 33010602011771号
浙公网安备 33010602011771号