
SUPRA:无须额外训练,将Transformer变为高效RNN,推理速度倍增
Transformers 已经确立了自己作为首要模型架构的地位,特别是因为它们在各种任务中的出色表现。但是Transformers 的内存密集型性质和随着词元数量的指数扩展推理成本带来了重大挑战。为了解决这些问题,论文“Linearizing Large Language Models”引入了一种创新的方法,称为UPtraining for Recurrent Attention (SUPRA)。该方法利用预训练的Transformers 并将其转换为递归神经网络,在保持预训练的好处的同时实现有效的推理。
SUPRA方法旨在将预训练的大型语言模型(LLMs)转化为RNNs,具体步骤包括替换softmax归一化为GroupNorm,使用一个小型MLP投影queries和keys。这种方法不仅降低了训练成本(仅为原来的5%),还利用了现有预训练模型的强大性能和数据。
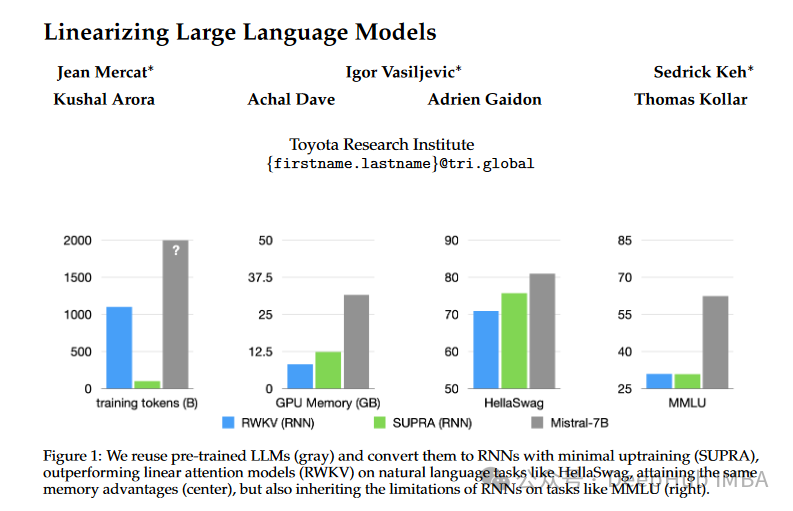
Transformers 面临着与序列长度线性增长的高推理成本。相比之下,rnn提供固定成本推理,因为它们能够保持恒定大小的隐藏状态,这使得它们对于需要高效和可扩展推理的任务具有吸引力。
https://avoid.overfit.cn/post/40da3737629348ff9d151d5774554d93

 浙公网安备 33010602011771号
浙公网安备 33010602011771号