Gradformer: 通过图结构归纳偏差提升自注意力机制的图Transformer
这是4月刚刚发布在arxiv上的论文,介绍了一种名为“Gradformer”的新型图Transformer,它在自注意力机制中引入了指数衰减掩码。以下是主要创新点:
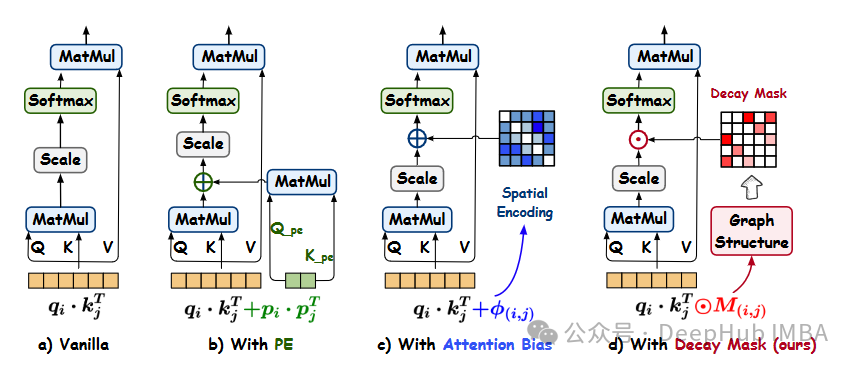
- 指数衰减掩码: Gradformer在其自注意力模块中集成了衰减掩码。该掩码随着图结构中节点之间的距离减小而呈指数递减。这种设计使模型能够在保留远距离信息捕获能力的同时,更专注于本地信息。
- 可学习约束: Gradformer为衰减掩码引入了一种可学习的约束,使不同的注意力头可以学习到不同的掩码。这使得注意力头多样化,提高了模型对图中多样结构信息的吸收能力。
- 归纳偏差的整合: Gradformer的设计将归纳偏差整合到自注意力机制中,增强了它对图结构化数据的建模能力。与之前仅使用位置编码或注意力偏差的方法相比,这种整合更有效。
- 与现有方法的比较: Gradformer在各种数据集上与14种基线模型进行了比较,包括图神经网络(GNN)和图Transformer模型。实验结果表明,Gradformer在图分类和回归等任务中,始终优于这些模型。
- 处理深层架构: Gradformer在深层架构中同样有效,随着网络深度的增加,其准确度得以保持甚至增强,这与其他转换器显著下降的准确度形成鲜明对比。
Gradformer通过引入带有可学习约束的指数衰减掩码,为图Transformer提供了一种新的方法,有效地捕捉了图结构中的本地和全局信息。这种设计将其与之前的模型区分开来,并提高了其在各种任务中的表现。
https://avoid.overfit.cn/post/ce4d852480a347ffb41c1eabf8cba71f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号