
5种常用于LLM的令牌遮蔽技术介绍以及Pytorch的实现
本文将介绍大语言模型中使用的不同令牌遮蔽技术,并比较它们的优点,以及使用Pytorch实现以了解它们的底层工作原理。
令牌掩码Token Masking是一种广泛应用于语言模型分类变体和生成模型训练的策略。BERT语言模型首先使用,并被用于许多变体(RoBERTa, ALBERT, DeBERTa…)。
而Text Corruption是一种更大的令牌遮蔽策略。在BART研究论文中,进行了大量实验来训练具有不同策略的编码器-解码器生成模型。
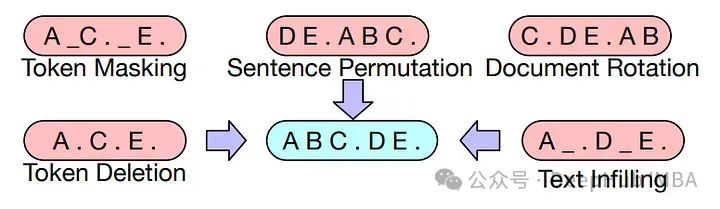
在进入正题之前,我们先介绍大型语言模型(llm)中掩码策略的背景
https://avoid.overfit.cn/post/1b9d2c9d6b9a4bacbe6fa906c23aee7f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号