大模型中常用的注意力机制GQA详解以及Pytorch代码实现
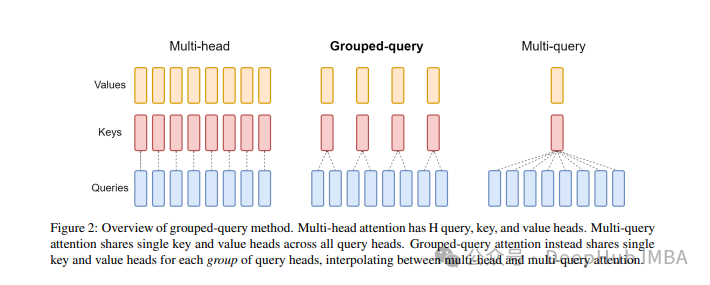
分组查询注意力 (Grouped Query Attention) 是一种在大型语言模型中的多查询注意力 (MQA) 和多头注意力 (MHA) 之间进行插值的方法,它的目标是在保持 MQA 速度的同时实现 MHA 的质量。
这篇文章中,我们将解释GQA的思想以及如何将其转化为代码。
GQA是在论文 GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints paper.中提出,这是一个相当简单和干净的想法,并且建立在多头注意力之上。
https://avoid.overfit.cn/post/58ee0d8f5ed14414bc856080ab748047

 浙公网安备 33010602011771号
浙公网安备 33010602011771号