BurstAttention:可对非常长的序列进行高效的分布式注意力计算
提高llm中注意力机制效率的努力主要集中在两种方法上:优化单设备计算和存储能力,如FlashAttention,以及利用多设备的分布式系统,如RingAttention。
FlashAttention通过使用静态随机存储器(SRAM)来存储中间状态,而不是依赖于高带宽存储器(HBM)来提高注意力计算速度。
而RingAttention通过将长序列划分为子序列并将其分布在多个设备上进行并行处理来处理长序列。
虽然它们都提高了处理速度和效率,如果将它们组合起来使用是否可以有更大的提高呢?理论上是这样,但是在分布式环境中直接组合这两种方法无法充分利用它们的优势,并且存在兼容性问题。
而最新的研究BurstAttention可以将2者结合,作为RingAttention和FlashAttention之间的桥梁。
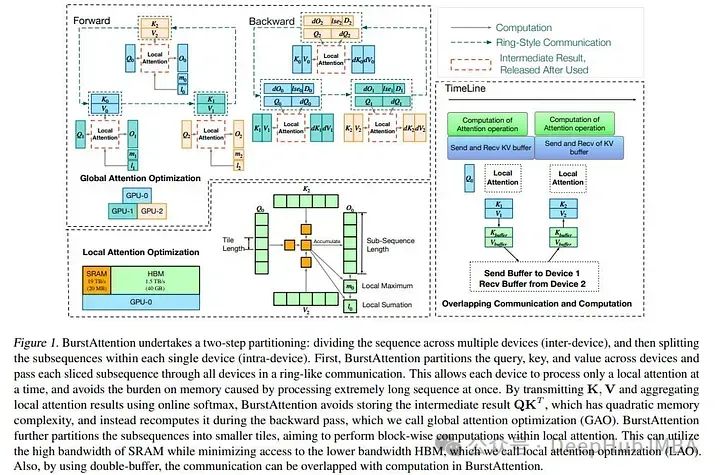
BurstAttention是一个创新的框架,它优化了跨设备的计算和通信,增强了内存使用,最小化了通信开销,提高了缓存效率。
https://avoid.overfit.cn/post/5aacdef85b104ff0a9faea9ad84f2a95

 浙公网安备 33010602011771号
浙公网安备 33010602011771号