文生图的基石CLIP模型的发展综述
CLIP的英文全称是Contrastive Language-Image Pre-training,即一种基于对比文本-图像对的预训练方法或者模型。CLIP是一种基于对比学习的多模态模型,CLIP的训练数据是文本-图像对:一张图像和它对应的文本描述,这里希望通过对比学习,模型能够学习到文本-图像对的匹配关系。
Open AI在2021年1月份发布的DALL-E和CLIP,这两个都属于结合图像和文本的多模态模型,其中DALL-E是基于文本来生成模型的模型,而CLIP是用文本作为监督信号来训练可迁移的视觉模型。
而Stable Diffusion模型中将CLIP文本编码器提取的文本特征通过cross attention嵌入扩散模型的UNet中,具体来说,文本特征作为attention的key和value,而UNet的特征作为query。也就是说CLIP其实是连接Stable Diffusion模型中文字和图片之间的桥梁。
CLIP
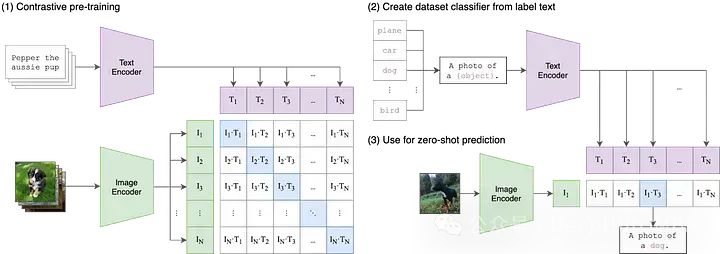
这是OpenAI在21年最早发布的论文,要想理解CLIP,我们需要将缩略词解构为三个组成部分:(1)Contrastive ,(2)Language-Image,(3)Pre-training。
https://avoid.overfit.cn/post/c98007d44f244cb6b875df25d759065d

 浙公网安备 33010602011771号
浙公网安备 33010602011771号