
微调大型语言模型进行命名实体识别
大型语言模型的目标是理解和生成与人类语言类似的文本。它们经过大规模的训练,能够对输入的文本进行分析,并生成符合语法和语境的回复。这种模型可以用于各种任务,包括问答系统、对话机器人、文本生成、翻译等。
命名实体识别(Named Entity Recognition,简称NER)是一种常见的应用方法,可以让模型学会识别文本中的命名实体,如人名、地名、组织机构名等。
大型语言模型在训练时通过大量的文本数据学习了丰富的语言结构和上下文信息。这使得模型能够更好地理解命名实体在文本中的上下文,提高了识别的准确性。即使模型在训练过程中没有见过某个命名实体,它也可以通过上下文推断该实体的类别。这意味着模型可以处理新的、未知的实体,而无需重新训练。除此以外我们还能通过微调(fine-tuning)在特定任务上进行优化。这种迁移学习的方法使得在不同领域和任务上进行NER更加高效。
这篇文章总结了命名实体识别(NER)问题微调大型语言模型的经验。我们将以个人身份信息(PII)为例来介绍大型语言模型进行NER微调的方法。
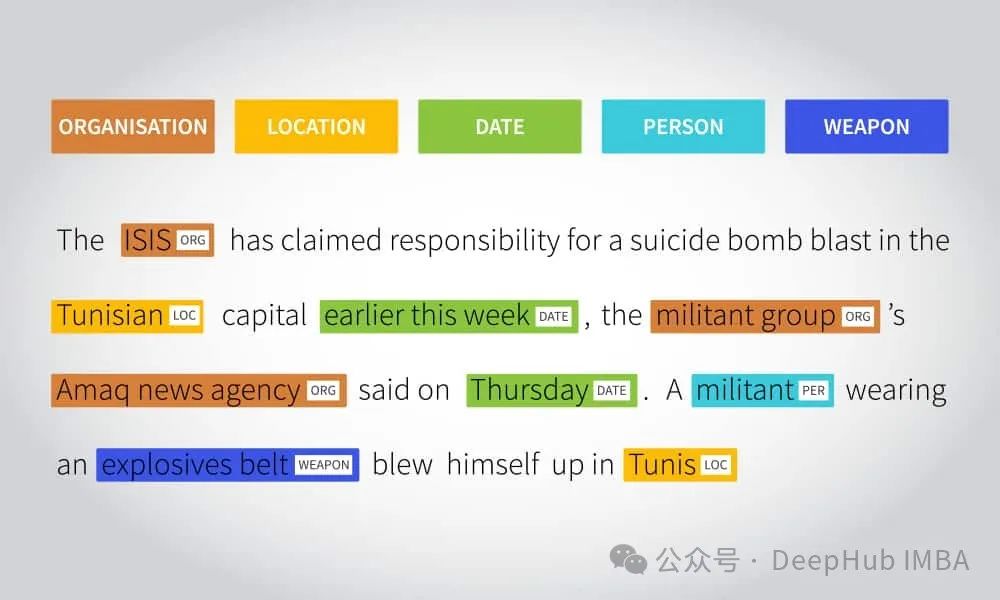
https://avoid.overfit.cn/post/0cb82b2fee6440b6b762a23bbf85bf59

 浙公网安备 33010602011771号
浙公网安备 33010602011771号