使用纹理对比度检测检测AI生成的图像
在本篇文章中我们将介绍如何开发一个深度学习模型来检测人工智能生成的图像
大多数用于检测人工智能生成图像的深度学习方法取决于生成图像的方法,或者取决于图像的性质/语义,其中模型只能检测人工智能生成的人、脸、汽车等特定对象。
但是这篇论文“Rich and Poor Texture Contrast: A Simple yet Effective Approach for AI-generated Image Detection”所提出的方法克服了上述问题,适用范围更广。我们将解释这篇论文,以及它是如何解决许多其他检测人工智能生成图像的方法所面临的问题的。
泛化性问题
当我们训练一个模型(如ResNet-50)来检测人工智能生成的图像时,模型会从图像的语义中学习。如果训练一个通过使用真实图像和人工智能生成的不同汽车图像来检测人工智能生成的汽车图像的模型,那么目前的模型只能从该数据中获得有关汽车的信息,而对于其他的物体就无法进行判别
虽然可以在各种对象的数据上进行训练,但当我们尝试这样做时,这种方法慢得多,并且只能够在未见过的数据上给出大约72%的准确率。虽然可以通过更多的训练和更多的数据来提高准确率,但我们不可能找到无穷无尽的数据进行训练。
也就是说目前检测模型的泛化性有很大的问题,为了解决这个问题,论文提出了以下的方法
Smash&Reconstruction
这篇论文提出了一种独特的方法来防止模型从图像的形状(在训练期间)学习人工智能生成的特征。它通过一个名为Smash&Reconstruction的方法来实现这一点。
在该方法将图像分成预定大小的小块,并对它们进行打乱洗牌生成形成新图像。这只是一个简单的解释,因为在形生成模型最终的输入图像之前还有一个额外的步骤。
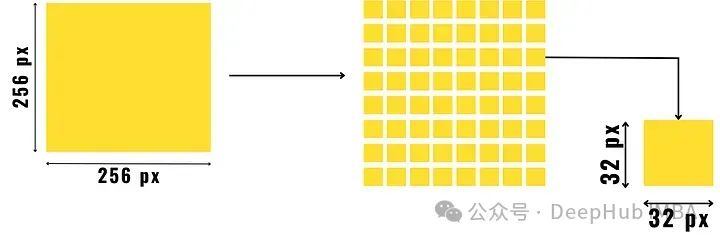
将图像分割成小块后,我们将小块分成两组,一组是纹理丰富的小块,另一组是纹理较差的小块。
https://avoid.overfit.cn/post/3aa6760ae9a9409896683fb17af7f876

 浙公网安备 33010602011771号
浙公网安备 33010602011771号