
自然语言生成任务中的5种采样方法介绍和Pytorch代码实现
在自然语言生成任务(NLG)中,采样方法是指从生成模型中获取文本输出的一种技术。本文将介绍常用的5中方法并用Pytorch进行实现。
束搜索(Beam Search)是贪婪解码的一种扩展,通过在每个时间步保留多个候选序列来克服贪婪解码的局部最优问题。
在每个时间步保留概率最高的前几个候选词语,然后在下一个时间步基于这些候选词语继续扩展,直到生成结束。束搜索通过考虑多个候选词语路径,可以在一定程度上增加生成文本的多样性。
在束搜索中,模型在每个时间步会生成多个候选序列,而不是仅选择一个最优序列。模型会根据当前已生成的部分序列和隐藏状态,预测下一个时间步可能的词语,并计算每个词语的条件概率分布。
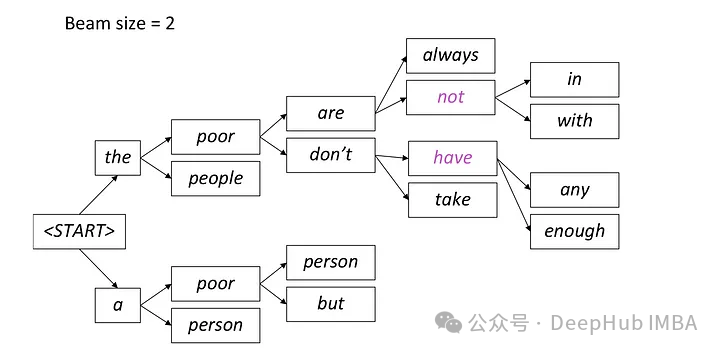
上图的每一步中,只保留两条最可能的路径(根据beam =2),而所有其他都被丢弃。此过程将继续进行,直到满足停止条件,该停止条件可以是生成序列结束令牌或达到最大序列长度的模型。最终输出将是最后一组路径中具有最高总体概率的序列。
https://avoid.overfit.cn/post/42c2631bc56347849d538768d84d47c2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号