
使用UMAP降维可视化RAG嵌入
大型语言模型(LLMs)如 GPT-4 已经展示了出色的文本理解和生成能力。但它们在处理领域特定信息方面面临挑战,比如当查询超出训练数据范围时,它们会产生错误的答案。LLMs 的推理过程也缺乏透明度,使用户难以理解达成结论的方式。
检索增强生成(RAG)在 LLMS 的工作流程中添加了一个检索步骤,使其能够在响应查询时从其他来源(如私人文本文档)中查询相关数据。这些文档事先分成小段,然后使用embedding的 ML 模型生成嵌入。具有相似内容的段将具有相似的嵌入。当 RAG 应用程序收到一个问题时,它使用查询检索相关文档片段。然后 LLMS 使用这些文档片段作为上下文来回答问题。这种方法可以提供回答查询所需的信息,并通过展示使用的片段来增加回答的透明度。
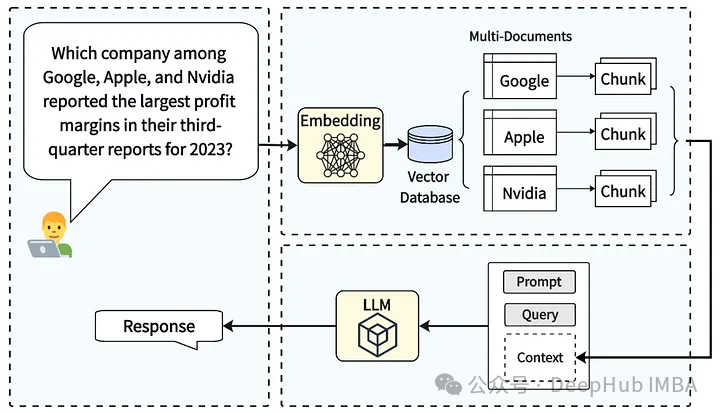
对于RAG来说,可视化嵌入空间是一个非常重要的方法,因为RAG应用程序使用该空间来查找相关信息。查询的结果与文档片空间息息相关,所以可以使用像UMAP这样的可视化方法,将高维嵌入减少到更易于展示的2D进行可视化。虽然高维嵌入被简化为两个分量,但问题及其相关文档片段在嵌入空间中形成簇,仍然是可以被识别出来,尤其是这时肉眼可见的,所以这有助于深入了解数据的本质。
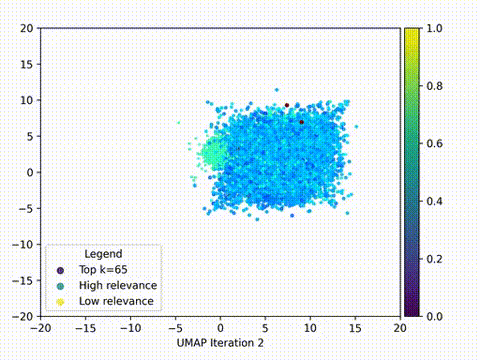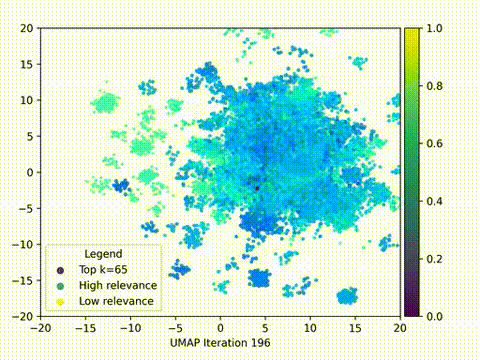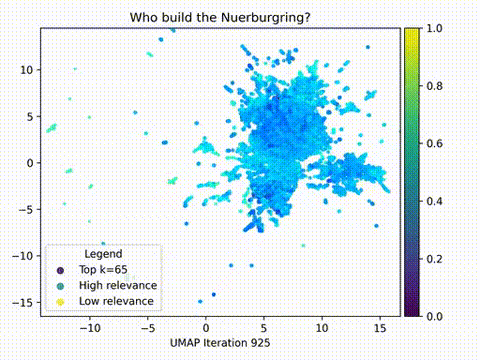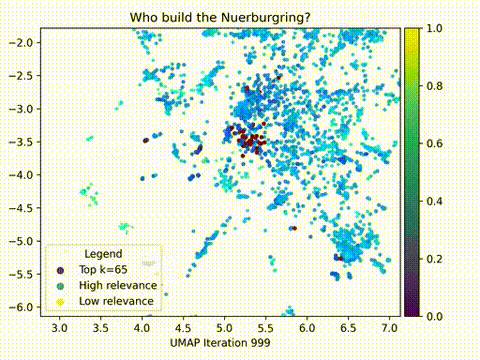
在本文中,我们将使用HTML格式的Wikipedia中的f1数据集,使用嵌入模型将它们转换为紧凑的矢量表示,并存储到ChromaDB中。使用LangChain构建RAG应用,并在2D中可视化嵌入,分析查询和文档片段之间的关系和接近度。
https://avoid.overfit.cn/post/31e45d66ef1547e397bbbef2ebcf38c8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号