使用SPIN技术对LLM进行自我博弈微调训练
2024年是大型语言模型(llm)的快速发展的一年,对于大语言模型的训练一个重要的方法是对齐方法,它包括使用人类样本的监督微调(SFT)和依赖人类偏好的人类反馈强化学习(RLHF)。这些方法在llm中发挥了至关重要的作用,但是对齐方法对人工注释数据有的大量需求。这一挑战使得微调成为一个充满活力的研究领域,研究人员积极致力于开发能够有效利用人类数据的方法。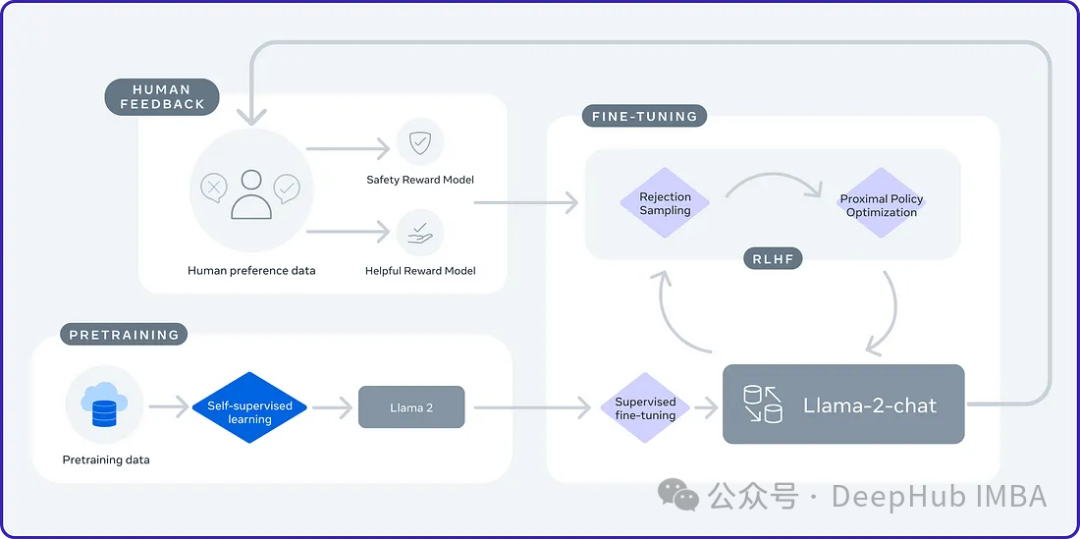
加州大学最近的一项研究介绍了一种名为SPIN(Self Play fIne tuNing)的新技术。SPIN从AlphaGo Zero和AlphaZero等游戏中成功的自我对弈机制中汲取灵感。它能够使LLM参与自我游戏的能力。这消除了对专业注释者的需求,无论是人类还是更高级的模型(如GPT-4)。SPIN涉及训练一个新的语言模型,并通过一系列迭代来区分它自己生成的响应和人类生成的响应。最终目标是开发得到一种语言模型,使其产生的反应与人类产生的反应没有区别。
https://avoid.overfit.cn/post/58fb890f7ffd4714b433e87bf7d42def

 浙公网安备 33010602011771号
浙公网安备 33010602011771号