Tokenization 指南:字节对编码,WordPiece等方法Python代码详解
在2022年11月OpenAI的ChatGPT发布之后,大型语言模型(llm)变得非常受欢迎。从那时起,这些语言模型的使用得到了爆炸式的发展,这在一定程度上得益于HuggingFace的Transformer库和PyTorch等库。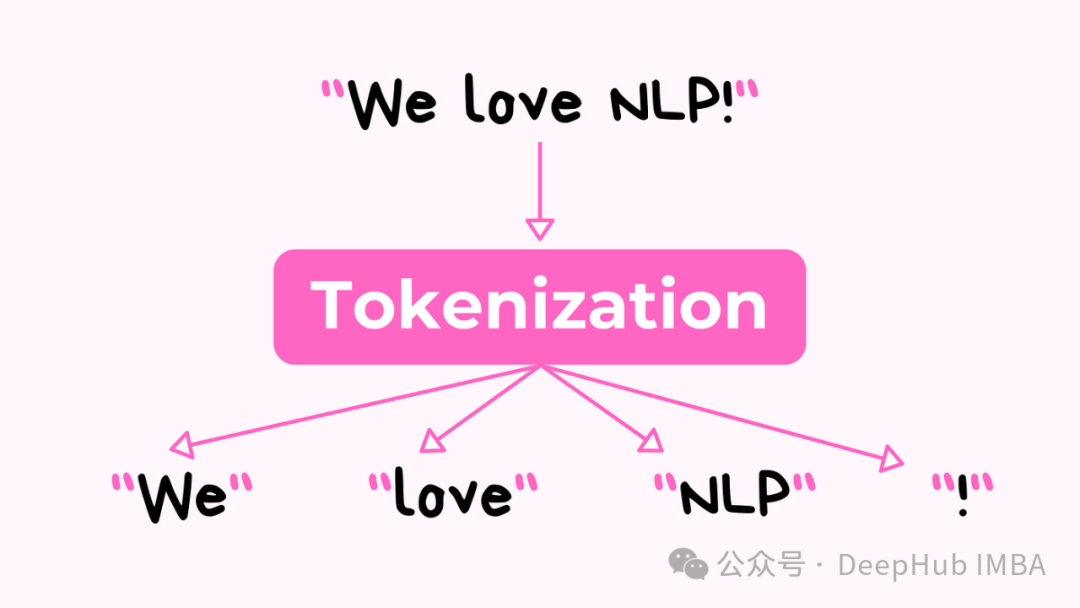
计算机要处理语言,首先需要将文本转换成数字形式。这个过程由一个称为标记化 Tokenization。
https://avoid.overfit.cn/post/c74166ceadac4adfa9aa65c135ea192f

 浙公网安备 33010602011771号
浙公网安备 33010602011771号