使用PyTorch实现去噪扩散模型
在深入研究去噪扩散概率模型(DDPM)如何工作的细节之前,让我们先看看生成式人工智能的一些发展,也就是DDPM的一些基础研究。
VAE
VAE 采用了编码器、概率潜在空间和解码器。在训练过程中,编码器预测每个图像的均值和方差。然后从高斯分布中对这些值进行采样,并将其传递到解码器中,其中输入的图像预计与输出的图像相似。这个过程包括使用KL Divergence来计算损失。VAEs的一个显著优势在于它们能够生成各种各样的图像。在采样阶段简单地从高斯分布中采样,解码器创建一个新的图像。
GAN
在变分自编码器(VAEs)的短短一年之后,一个开创性的生成家族模型出现了——生成对抗网络(GANs),标志着一类新的生成模型的开始,其特征是两个神经网络的协作:一个生成器和一个鉴别器,涉及对抗性训练过程。生成器的目标是从随机噪声中生成真实的数据,例如图像,而鉴别器则努力区分真实数据和生成数据。在整个训练阶段,生成器和鉴别器通过竞争性学习过程不断完善自己的能力。生成器生成越来越有说服力的数据,从而比鉴别器更聪明,而鉴别器又提高了辨别真实样本和生成样本的能力。这种对抗性的相互作用在生成器生成高质量、逼真的数据时达到顶峰。在采样阶段,经过GAN训练后,生成器通过输入随机噪声产生新的样本。它将这些噪声转换为通常反映真实示例的数据。
为什么我们需要另一个模型架构
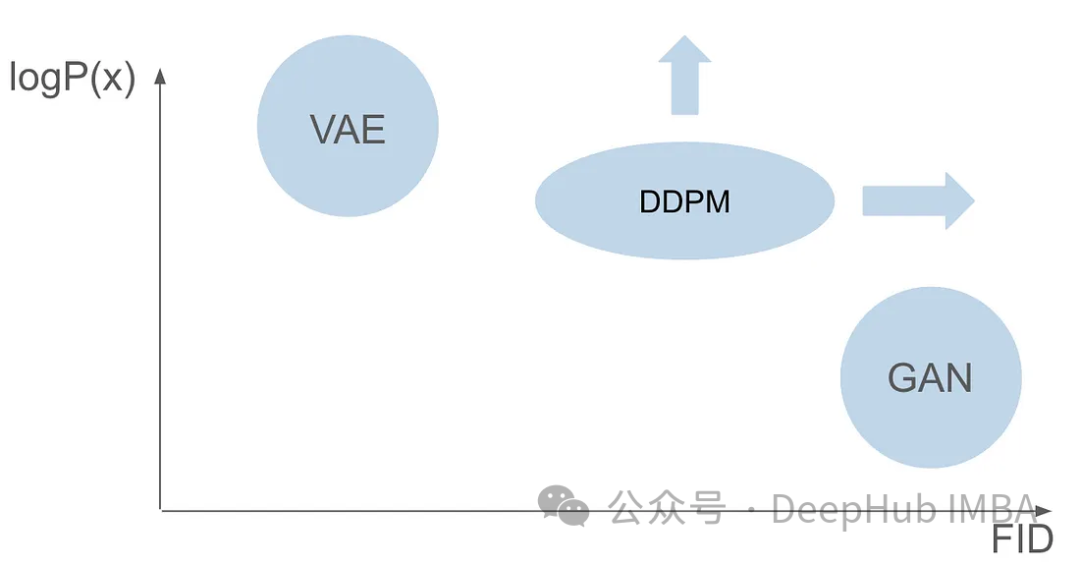
两种模型都有不同的问题,虽然GANs擅长于生成与训练集中的图像非常相似的逼真图像,但VAEs擅长于创建各种各样的图像,尽管有产生模糊图像的倾向。但是现有的模型还没有成功地将这两种功能结合起来——创造出既高度逼真又多样化的图像。这一挑战给研究人员带来了一个需要解决的重大障碍。
在第一篇GAN论文发表六年后,在VAE论文发表七年后,一个开创性的模型出现了:去噪扩散概率模型(DDPM)。DDPM结合了两个世界的优势,擅长于创造多样化和逼真的图像。
在本文中,我们将深入研究DDPM的复杂性,涵盖其训练过程,包括正向和逆向过程,并探索如何执行采样。在整个探索过程中,我们将使用PyTorch从头开始构建DDPM,并完成其完整的训练。
https://avoid.overfit.cn/post/6a872db579a146f1a125b749ba5f4b2b

 浙公网安备 33010602011771号
浙公网安备 33010602011771号