处理不平衡数据的过采样技术对比总结
在不平衡数据上训练的分类算法往往导致预测质量差。模型严重偏向多数类,忽略了对许多用例至关重要的少数例子。这使得模型对于涉及罕见但高优先级事件的现实问题来说不切实际。
过采样提供了一种在模型训练开始之前重新平衡类的方法。通过复制少数类数据点,过采样平衡了训练数据,防止算法忽略重要但数量少的类。虽然存在过拟合风险,但过采样可以抵消不平衡学习的负面影响,可以让机器学习模型获得解决关键用例的能力
常见的过采样技术包括随机过采样、SMOTE(合成少数过采样技术)和ADASYN(不平衡学习的自适应合成采样方法)。随机过采样简单地复制少数样本,而SMOTE和ADASYN策略性地生成合成的新数据来增强真实样本。
什么是过采样
过采样是一种数据增强技术,用于解决类不平衡问题(其中一个类的数量明显超过其他类)。它旨在通过扩大属于代表性不足的类别的样本量来重新平衡训练数据分布。
过采样通过复制现有样本或生成合成的新数据点来增加少数类样本。这是通过复制真实的少数观察结果或根据真实世界的模式创建人工添加来实现的。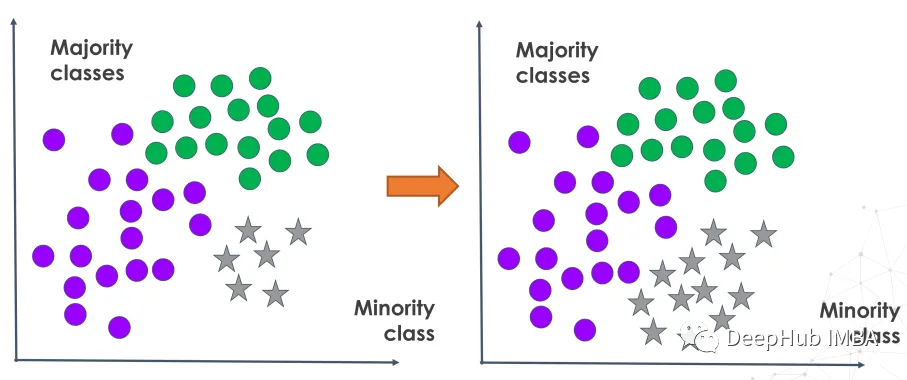
在模型训练之前通过过采样放大代表性不足的类别,这样模型学习可以更全面地代表所有类别,而不是严重倾向于占主导地位的类别。这改进了用于解决涉及检测重要但不常见事件的需求的各种评估度量。
https://avoid.overfit.cn/post/1814d699b1574f258fd3aea341d9e487

 浙公网安备 33010602011771号
浙公网安备 33010602011771号