2023年小型计算机视觉总结
在过去的十年中,出现了许多涉及计算机视觉(CV)的项目,无论是小型的概念验证项目还是更大规模的生产应用。应用计算机视觉的方法是相当标准化的:
1、定义问题(分类、检测、跟踪、分割)、输入数据(图片的大小和类型、视野)和类别(正是我们想要的)
2、注释一些图片
3、选择一个网络架构,训练-验证,得到一些统计数据
4、构建推理系统并进行部署
到2023年底,人工智能领域迎来了生成式人工智能的新成功:大型语言模型(llm)和图像生成模型。每个人都在谈论它,它们对小型计算机视觉应用有什么改变吗?
本文将探索是否可以利用它们来构建数据集,利用新的架构和新的预训练权重,或者从大模型中提取知识。
小型计算机视觉
在这里,我们通常感兴趣的是可以以相对较小的规模构建和部署的应用程序:
💰开发成本不应该太高
💽它不应该需要一个庞大的基础设施来训练(想想计算能力和数据规模)
🧑🔬它不需要很强的研究技能,而是应用现有的技术
⚡推理应该是轻量级和快速的,以便它可以嵌入或部署在CPU服务器上
🌍总体环境足迹应该很小(考虑计算能力,模型/数据的一般大小,没有特定的硬件要求)
这显然不是当今人工智能的趋势,因为我们在今年看到的都是具有数十亿个参数的模型,并且这些模型开始成为某些应用程序的标准。但重要的是:关心更小的规模是至关重要的,并不是所有的项目都应该遵循谷歌、Meta、OpenAI或微软的规模趋势并且我们也不可能有它们那么大的资金。
目前来看大多数有趣的计算机视觉项目实际上也比那些大公司的项目规模要小得多,但这并不意味着我们就要缩小我们的应用程序,而是说我们应该更加关心开发和推理成本。所以考虑到这一点,我们还能在应用中利用人工智能的最新发展吗?
首先看看基础模型
计算机视觉中的基础模型
新的大型语言模型(LLM)已经很流行,因为你可以很容易地在应用程序中使用基础模型(许多是开源的,或者可以通过API使用)。把GPT、Bert、Llama看作这样的模型。基础模型是一个非常大的通用神经网络,它是大多数下游任务的基础。它包含了非常广泛的主题,语义,语法,不同的语言等知识。
在计算机视觉中,这样的模型已经存在了很长一段时间了:使用ImageNet(100万张标记图像)上预训练的神经网络作为下游任务的“基础”模型是标准的。你可以在它的基础上构建你的神经网络,如果需要的话,还可以根据你自己的数据对它进行微调。
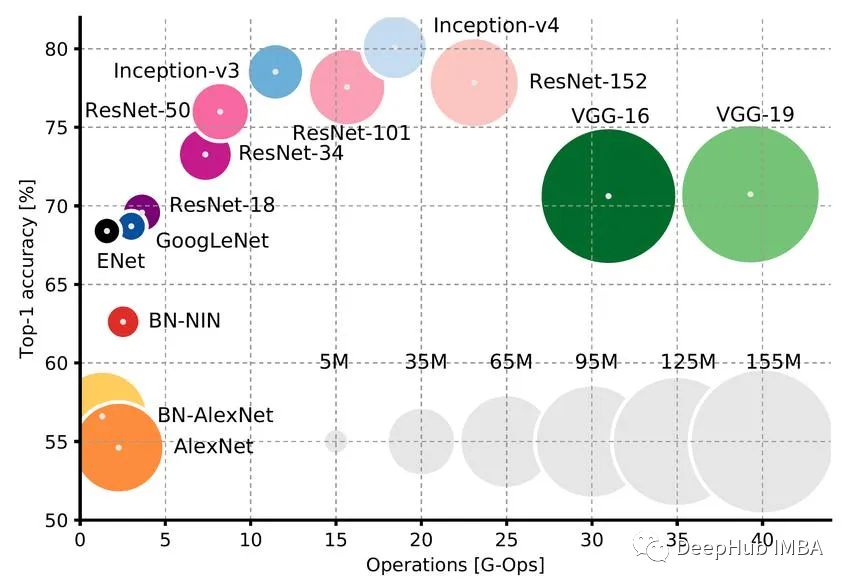
ImageNet预训练网络和llm之间有两个主要的概念区别:
https://avoid.overfit.cn/post/27697c284d4f4a4d93f91be616e3e998

 浙公网安备 33010602011771号
浙公网安备 33010602011771号