从头开始实现LoRA以及一些实用技巧
LoRA是Low-Rank Adaptation或Low-Rank Adaptors的缩写,它提供了一种用于对预先存在的语言模型进行微调的高效且轻量级的方法。
LoRA的主要优点之一是它的效率。通过使用更少的参数,lora显著降低了计算复杂度和内存使用。这使我们能够在消费级gpu上训练大型模型,并将我们的lora(以兆字节计)分发给其他人。
lora可以提高泛化性能。通过限制模型的复杂性,它们有助于防止过拟合,特别是在训练数据有限的情况下。这就产生了更有弹性的模型,这些模型在处理新的、看不见的数据时表现出色,或者至少保留了它们最初训练任务中的知识。
LoRA可以无缝集成到现有的神经网络架构中。这种集成允许以最小的额外训练成本对预训练模型进行微调和适应,使它们非常适合迁移学习应用。
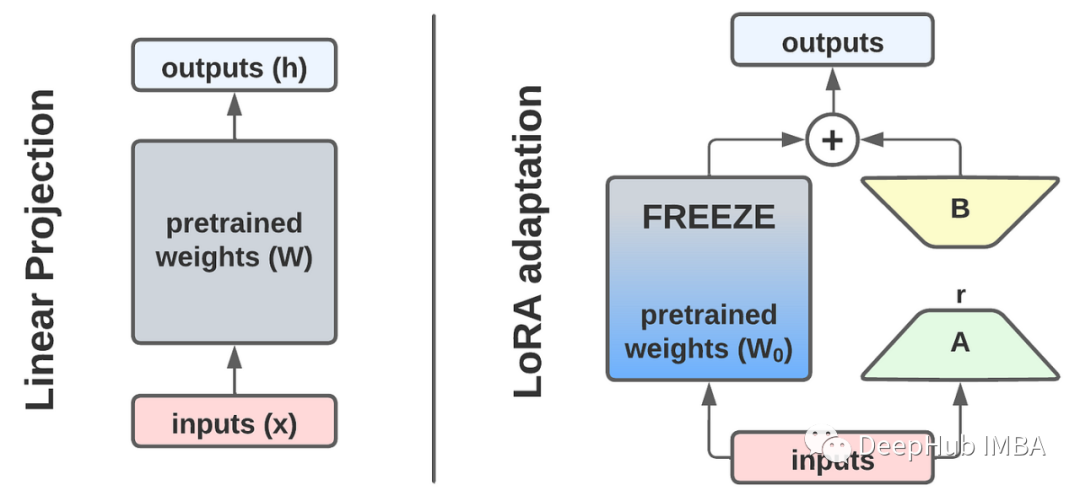
本文将首先深入研究LoRA,然后以RoBERTa模型例从头开发一个LoRA,然后使用GLUE和SQuAD基准测试对实现进行基准测试,并讨论一些技巧和改进。
https://avoid.overfit.cn/post/ed4e5c208ab64a4d9296f5667dfe50ac

 浙公网安备 33010602011771号
浙公网安备 33010602011771号