
使用PyTorch II的新特性加快LLM推理速度
Pytorch团队提出了一种纯粹通过PyTorch新特性在的自下而上的优化LLM方法,包括:
Torch.compile: PyTorch模型的编译器
GPU量化:通过降低精度操作来加速模型
推测解码:使用一个小的“草稿”模型来加速llm来预测一个大的“目标”模型的输出
张量并行:通过在多个设备上运行模型来加速模型。
我们来看看这些方法的性能比较:
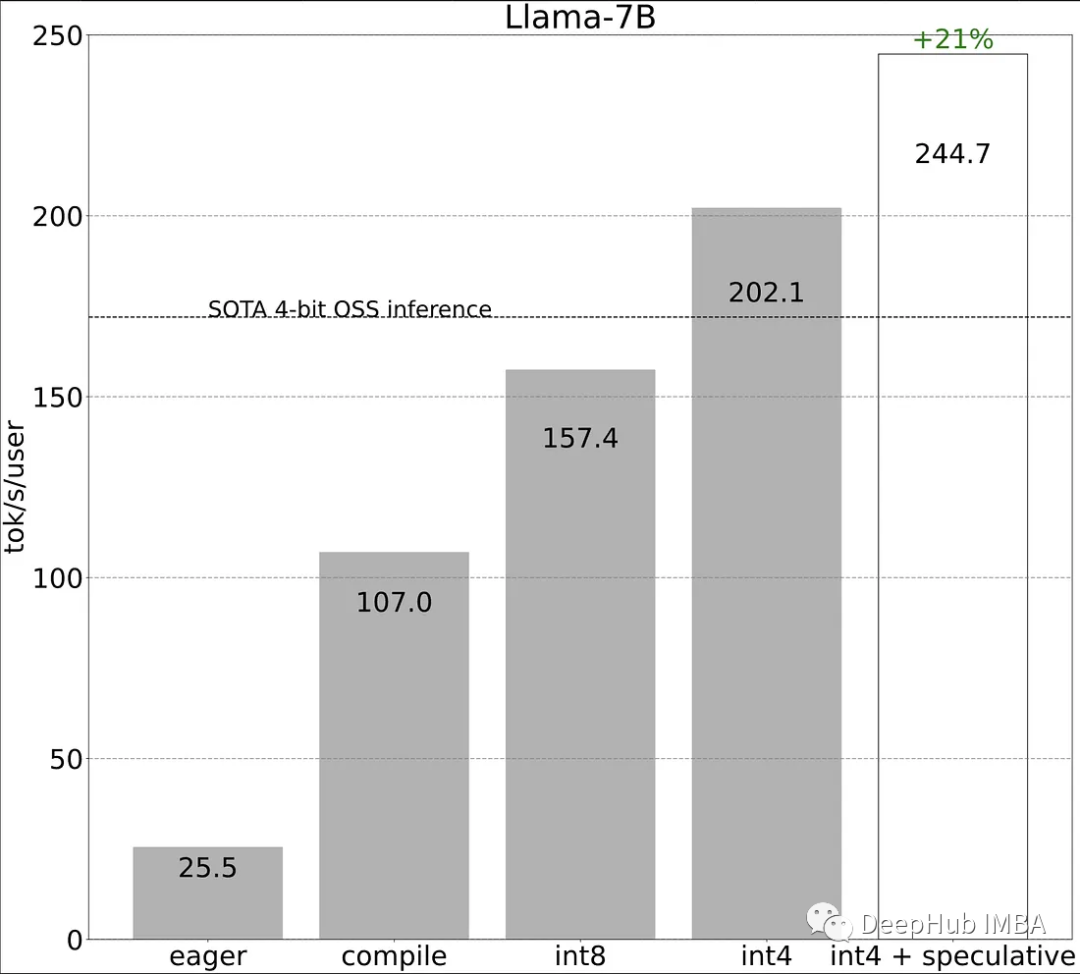
作为对比,传统的方式进行LLaMA-7b的推理性能为25tokens/秒,我们来看看看这些方法对推理性能的提高。
https://avoid.overfit.cn/post/58c4ba8ee4f546ca81744c50733e46d9

 浙公网安备 33010602011771号
浙公网安备 33010602011771号