
斯坦福大学引入FlashFFTConv来优化机器学习中长序列的FFT卷积
斯坦福大学的FlashFFTConv优化了扩展序列的快速傅里叶变换(FFT)卷积。该方法引入Monarch分解,在FLOP和I/O成本之间取得平衡,提高模型质量和效率。并且优于PyTorch和FlashAttention-v2。它可以处理更长的序列,并在人工智能应用程序中打开新的可能性。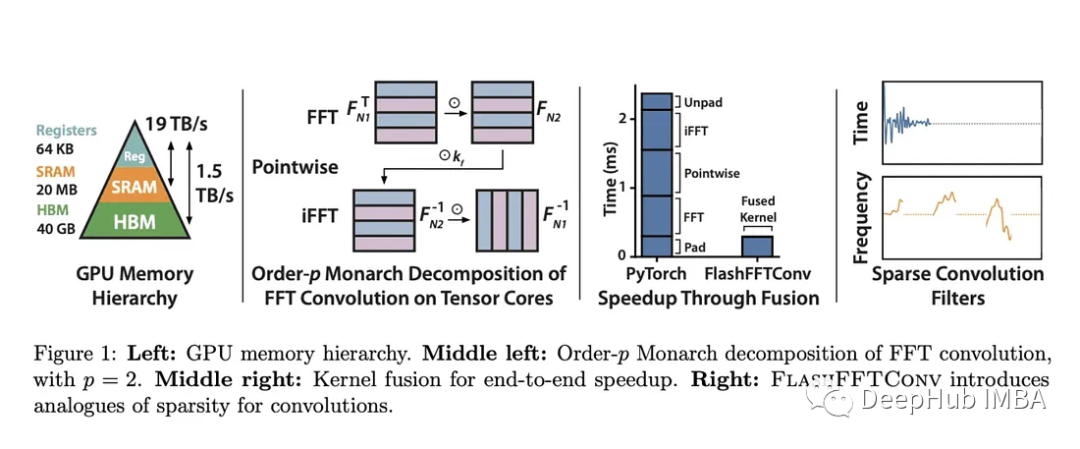
处理长序列的效率一直是机器学习领域的一个挑战。卷积神经网络(cnn)最近作为序列建模的关键工具获得了突出的地位,在从自然语言处理到计算机视觉和遗传学的各个领域都提供了一流的性能。尽管卷积序列模型具有卓越的品质,但在速度方面仍落后于Transformers 。
快速傅里叶变换(FFT)卷积算法,通过在频域内计算输入序列和核之间的卷积,可以解决上面卷积的问题。但是FFT卷积在执行时间方面有非常大的问题。
https://avoid.overfit.cn/post/de29ba25d1c94218b1c9da494b5e58c3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号