

大语言模型量化方法对比:GPTQ、GGUF、AWQ
在过去的一年里,大型语言模型(llm)有了飞速的发展,在本文中,我们将探讨几种(量化)的方式,除此以外,还会介绍分片及不同的保存和压缩策略。
说明:每次加载LLM示例后,建议清除缓存,以防止出现OutOfMemory错误。
del model, tokenizer, pipeimport torchtorch.cuda.empty_cache()
如果在jupyter中无法释放显存,请重启这个jupyter notebook。
模型加载
加载LLM的最直接、最普通的方式是通过🤗Transformers。HuggingFace已经创建了一个套件,我们能够直接使用
pip install git+https://github.com/huggingface/transformers.gitpip install accelerate bitsandbytes xformers
安装完成后,我们可以使用以下管道轻松加载LLM:
from torch import bfloat16from transformers import pipeline# Load in your LLM without any compression trickspipe = pipeline("text-generation",model="HuggingFaceH4/zephyr-7b-beta",torch_dtype=bfloat16,device_map="auto")
我们这里使用zephyr-7b-beta作为示例
这种加载LLM的方法通常不会执行任何压缩技巧。我们来做个使用的示例
messages = [{"role": "system","content": "You are a friendly chatbot.",},{"role": "user","content": "Tell me a funny joke about Large Language Models."},]prompt = pipe.tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True)
使用内部提示模板生成的提示是这样构造的:
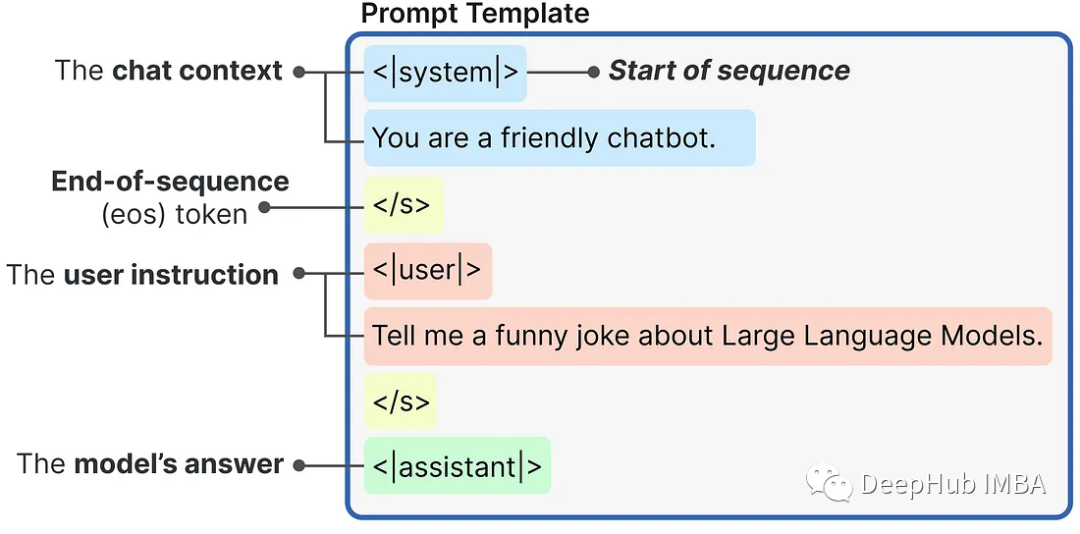
然后,我们可将提示传递给LLM来生成答案:
https://avoid.overfit.cn/post/47f8871b7144405795301aa0a6bd9a24



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)
2022-11-16 经典CNN设计演变的关键总结:从VGGNet到EfficientNet