
Spectron: 谷歌的新模型将语音识别与语言模型结合进行端到端的训练
Spectron是谷歌Research和Verily AI开发的新的模型。与传统的语言模型不同,Spectron直接处理频谱图作为输入和输出。该模型消除归纳偏差,增强表征保真度,提高音频生成质量。
它采用预训练的语音编码器和语言解码器,提供文本和语音的延续。但是频谱图帧生成比较费时并且无法并行文本和频谱图解码。
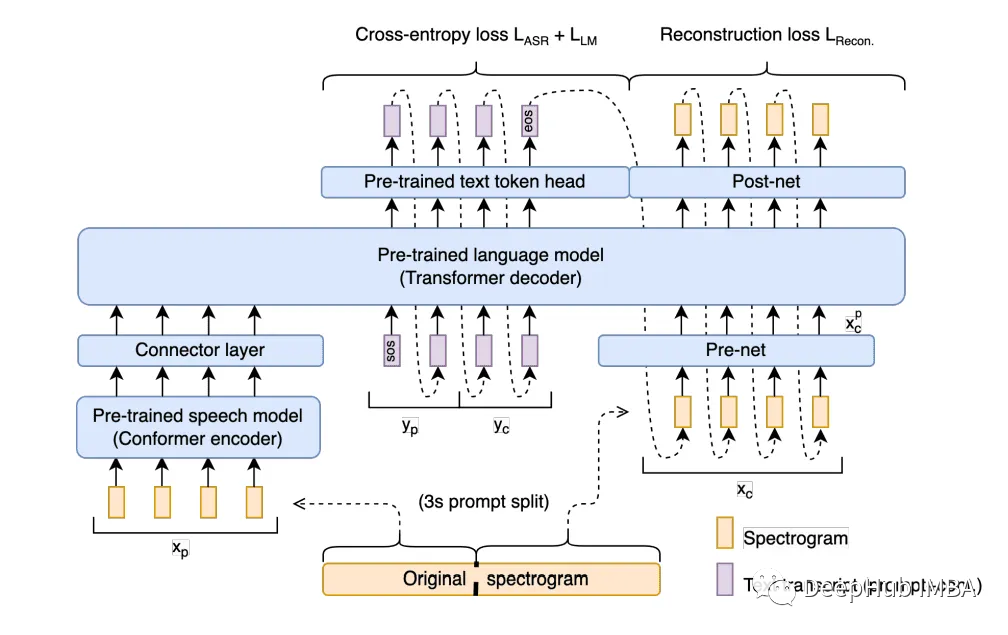
传统上,像GPT-3这样的LLM依赖于深度学习架构,在大量文本数据集上进行预训练,使他们能够掌握人类语言的复杂性,并生成与上下文相关且连贯的文本。而谷歌Research和Verily AI推出了一种新型口语模型Spectron。通过赋予LLM预训练的语音编码器,模型能够接受语音输入并生成语音输出。
https://avoid.overfit.cn/post/c7c1399fd35f43feadba645e3af85da8

 浙公网安备 33010602011771号
浙公网安备 33010602011771号