10月发布的5篇人工智能论文推荐
JudgeLM: Fine-tuned Large Language Models are Scalable Judges
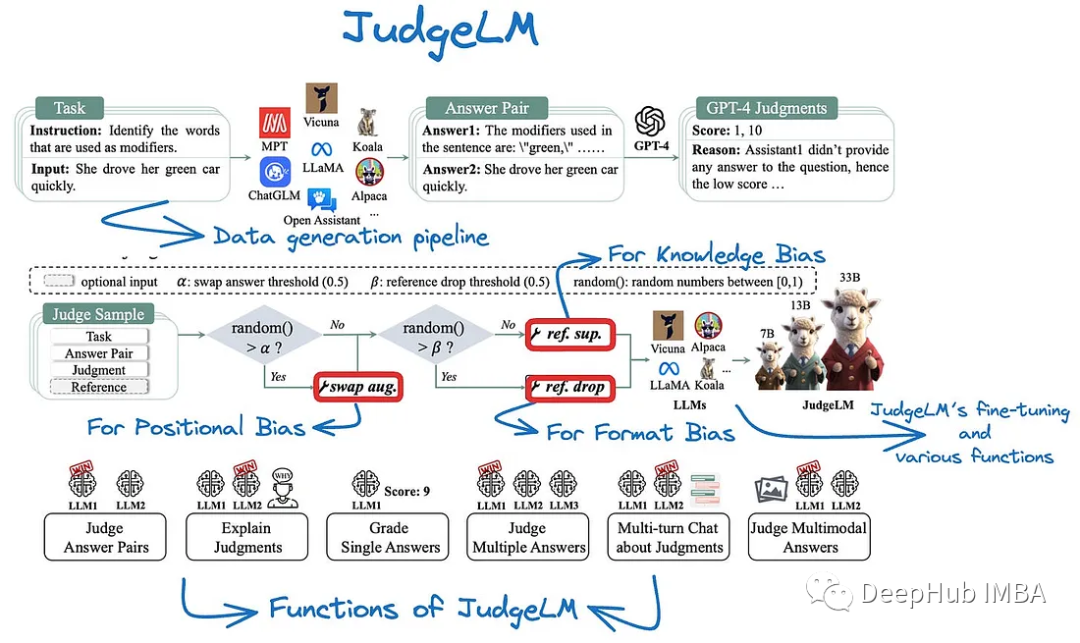
由于现有基准和指标的限制,在开放式环境中评估大型语言模型(llm)是一项具有挑战性的任务。为了克服这一挑战,本文引入了微调llm作为可扩展“法官”的概念,称为JudgeLM,这样可以在开放式基准场景中有效地评估llm。该方法结合了大量高质量的法官模型数据集,包括不同的种子任务、LLM生成的响应和GPT-4的详细判断,从而为LLM评估的未来研究奠定了基础。JudgeLM作为一种可扩展的语言模型法官,其一致性水平超过90%,超过了人与人之间的一致性。该模型在处理各种任务时也表现出适应性。该分析解决了LLM判断微调固有的偏差,并介绍了增强不同情况下模型一致性的方法,从而增强了JudgeLM的可靠性和灵活性。
https://avoid.overfit.cn/post/cafc3d29d3704ada89bf9659a38113b6

 浙公网安备 33010602011771号
浙公网安备 33010602011771号