
VeRA: 性能相当,但参数却比LoRA少10倍
2022年的LoRA提高了微调效率,它在模型的顶部添加低秩(即小)张量进行微调。模型的参数被冻结。只有添加的张量的参数是可训练的。
与标准微调相比,它大大减少了可训练参数的数量。例如,对于Llama 27b, LoRA通常训练400万到5000万个参数,这比标准微调则训练70亿个参数药效的多。还可以使用LoRA来微调量化模型,例如,使用QLoRA:
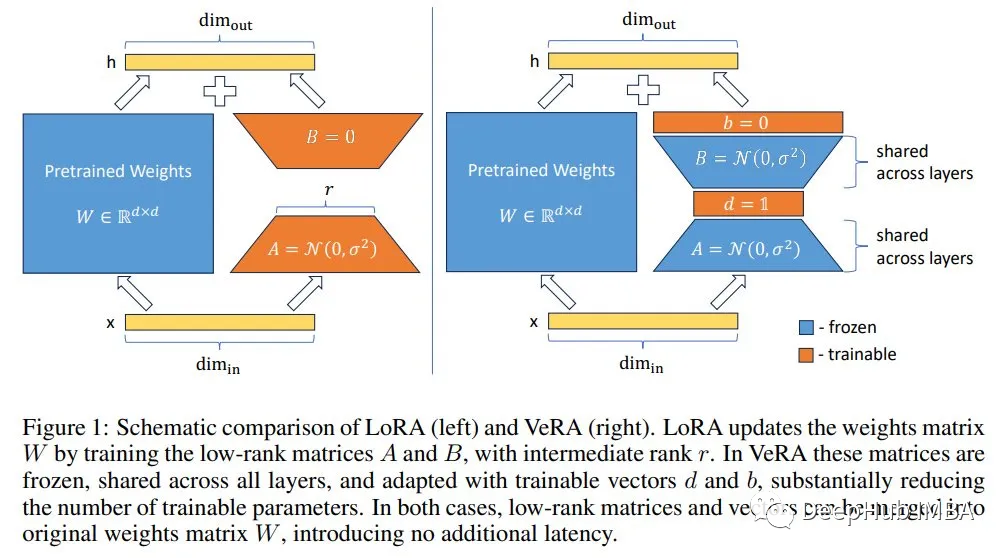
虽然LoRA可训练参数的数量可能比模型参数小的多。但它随着张量(在LoRA中通常表示为r)的秩和目标模块的数量而增加。如果我们想要以大秩r(假设大于64)和模型的所有模块为目标(达到最佳性能),那么我们可能仍然需要训练数亿个参数。
本周又发布了VeRA,以进一步减少LoRA可训练参数的数量。
https://avoid.overfit.cn/post/0c18ad6b818c4e11ae5c54825ef4857a

 浙公网安备 33010602011771号
浙公网安备 33010602011771号