
XGBoost 2.0:对基于树的方法进行了重大更新
XGBoost是处理不同类型表格数据的最著名的算法,LightGBM 和Catboost也是为了修改他的缺陷而发布的。9月12日XGBoost发布了新的2.0版,本文除了介绍让XGBoost的完整历史以外,还将介绍新机制和更新。
这是一篇很长的文章,因为我们首先从梯度增强决策树开始。
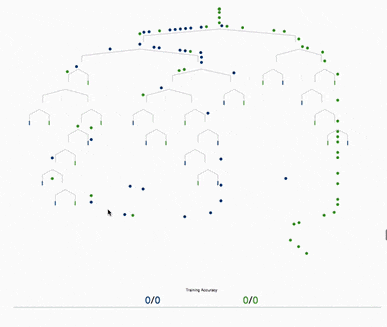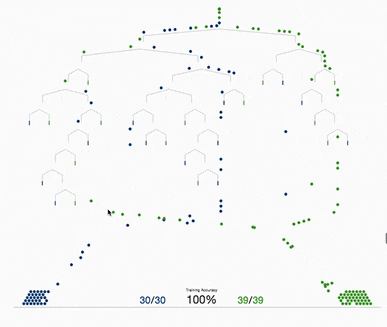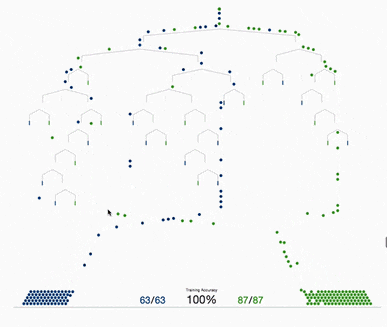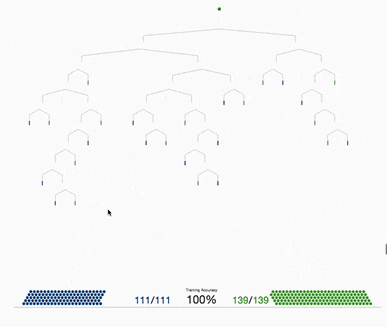
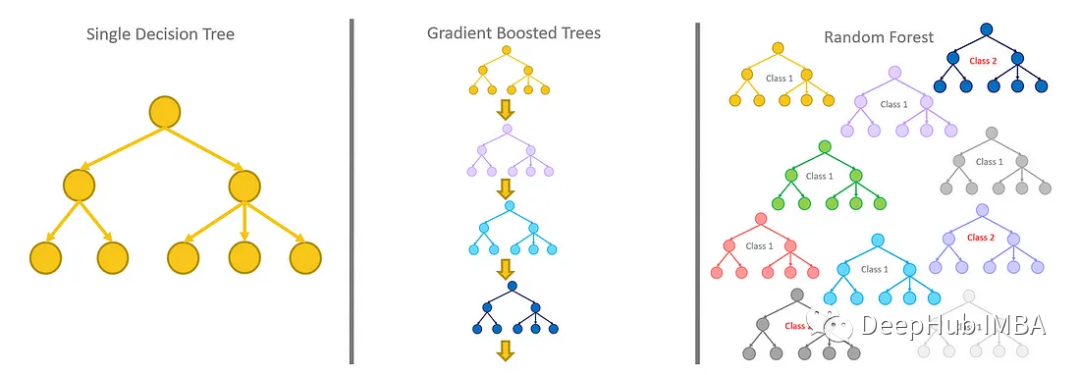
基于树的方法,如决策树、随机森林以及扩展后的XGBoost,在处理表格数据方面表现出色,这是因为它们的层次结构天生就善于对表格格式中常见的分层关系进行建模。它们在自动检测和整合特征之间复杂的非线性相互作用方面特别有效。另外这些算法对输入特征的规模具有健壮性,使它们能够在不需要规范化的情况下在原始数据集上表现良好。
最终要的一点是它们提供了原生处理分类变量的优势,绕过了对one-hot编码等预处理技术的需要,尽管XGBoost通常还是需要数字编码。
另外还有一点是基于树的模型可以轻松地可视化和解释,这进一步增加了吸引力,特别是在理解表格数据结构时。通过利用这些固有的优势,基于树的方法——尤其是像XGBoost这样的高级方法——非常适合处理数据科学中的各种挑战,特别是在处理表格数据时。
https://avoid.overfit.cn/post/64350d0c3f774c0f98ad3d32348a08b5

 浙公网安备 33010602011771号
浙公网安备 33010602011771号