
LongLoRA:不需要大量计算资源的情况下增强了预训练语言模型的上下文能力
麻省理工学院和香港中文大学推出了LongLoRA,这是一种革命性的微调方法,可以在不需要大量计算资源的情况下提高大量预训练语言模型的上下文能力。
LongLoRA是一种新方法,它使改进大型语言计算机程序变得更容易,成本更低。训练LLM往往需要大量信息和花费大量的时间和计算机能力。使用大量数据(上下文长度为8192)进行训练所需的计算机能力是使用较少数据(上下文长度为2048)的16倍。
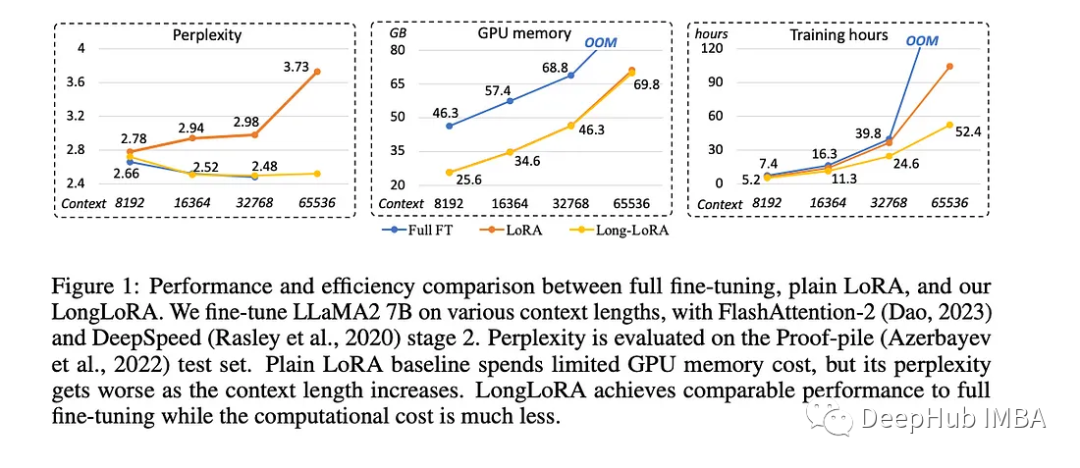
LongLoRA的研究论文中,作者分享了使这一过程更快、更便宜的两个想法。
https://avoid.overfit.cn/post/7b79c4325ff24114ad634a52d286f4f2

 浙公网安备 33010602011771号
浙公网安备 33010602011771号