
Stability AI发布基于稳定扩散的音频生成模型Stable Audio
近日Stability AI推出了一款名为Stable Audio的尖端生成模型,该模型可以根据用户提供的文本提示来创建音乐。在NVIDIA A100 GPU上Stable Audio可以在一秒钟内以44.1 kHz的采样率产生95秒的立体声音频,与原始录音相比,该模型处理时间的大幅减少归因于它对压缩音频潜在表示的有效处理。
架构
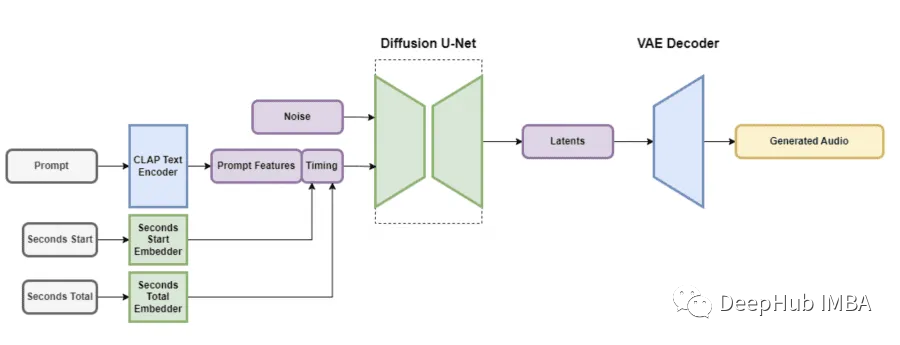
自动编码器(VAE),一个文本编码器和U-Net扩散模型。VAE通过获取输入音频数据并表示为保留足够信息用于转换的压缩格式,因为使用了卷积结构,所以不受描述音频编解码器的影响,可以有效地编码和解码可变长度的音频,同时保持高输出质量。
https://avoid.overfit.cn/post/86c750a6534b4cd380c94d3301fcf1bd

 浙公网安备 33010602011771号
浙公网安备 33010602011771号