
SplitMask:大规模数据集是自我监督预训练的必要条件吗?
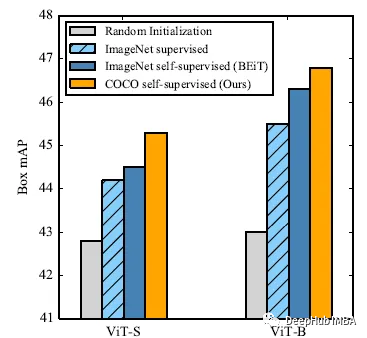
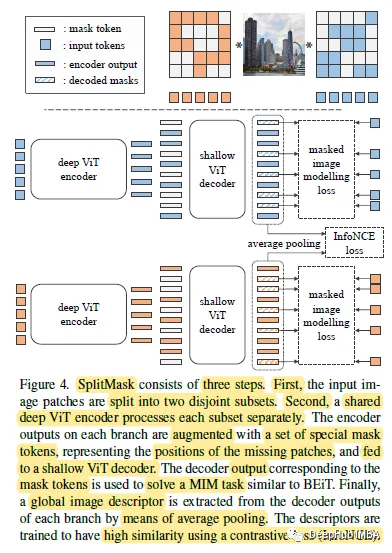
自监督预训练需要大规模数据集吗?这是2021年发布的一篇论文,它在自监督预训练场景中使用小数据集,如Stanford Cars, Sketch或COCO,它们比ImageNet小几个数量级。并提出了一种类似于BEiT的去噪自编码器的变体SplitMask,它对预训练数据的类型和大小具有更强的鲁棒性。
SplitMask
https://avoid.overfit.cn/post/21d79b50015d406694bcf063b12c02e3

 浙公网安备 33010602011771号
浙公网安备 33010602011771号